konfidensintervall och p-värden
för att underhålla någon diskussion om statistisk analys är det viktigt att först förstå begreppet befolkningsstatistik. Tydligt, befolkningsstatistik är värdena för varje åtgärd inom befolkningen av intresse, och att uppskatta dem är målet för de flesta studier ., Till exempel, i en studie som tittar på fetma för patienter på en viss medicinering, kan befolkningsstatistiken vara den genomsnittliga fetma för alla patienter på medicinen.
för att identifiera detta värde krävs dock data för varje enskild individ som ingår i denna kategori, vilket är opraktiskt. I stället kan ett randomiserat prov samlas in, från vilket provstatistik kan erhållas. Dessa provstatistik tjänar som uppskattningar av motsvarande befolkningsstatistik och gör det möjligt för en forskare att dra slutsatser om en population av intresse.,
det finns en betydande begränsning genom att dessa konstruerade prover måste vara representativa för den större intressepopulationen. Även om det finns många steg som kan vidtas för att minska denna begränsning, går ibland dess effekter (så kallad provtagning bias ) bortom forskarens kontroll. Dessutom kan randomisering, även i en teoretisk situation utan provtagning, resultera i ett felaktigt representativt prov. I föregående exempel, anta att befolkningstakten av fetma bland alla vuxna som är berättigade till medicinen var 25%., I ett enkelt slumpmässigt urval av 30 patienter från denna population finns det en 19,7% chans att minst 10 patienter kommer att vara överviktiga, vilket resulterar i en provfetma på 33,3% eller ännu högre. Även om det inte finns något samband mellan medicinering och fetma, är det fortfarande möjligt att stöta på en hastighet som verkar skilja sig från den totala fetma, som inträffade genom slumpmässighet i provtagning ensam. Denna effekt är orsaken till rapportering av konfidensintervall och p-värden i klinisk forskning.
konfidensintervall är intervall där befolkningsstatistiken kan ligga., De är konstruerade på grundval av provstatistiken och vissa egenskaper hos provet som mäter hur sannolikt det är att det är representativt och rapporteras till ett visst tröskelvärde . Ett 95% konfidensintervall är ett intervall konstruerat så att 95% av slumpmässiga prover i genomsnitt skulle innehålla den sanna populationsstatistiken inom deras 95% konfidensintervall. Således tas ett tröskelvärde för signifikanta resultat ofta som 95%, med insikten att alla värden inom det rapporterade intervallet är lika giltiga som den möjliga befolkningsstatistiken.,
p-värdet rapporterar liknande information på ett annat sätt. I stället för att bygga ett intervall kring en provstatistik rapporterar ett p-värde sannolikheten att provstatistiken producerades från slumpmässig provtagning av en population, med tanke på en uppsättning antaganden om befolkningen, kallad ”nollhypotesen” ., Med exempelstudien om fetma igen kan fetma bland provet (ett urval av patienter på medicinen) rapporteras tillsammans med ett p-värde som bestämmer chansen att en sådan hastighet skulle kunna produceras från slumpmässigt provtagning av den totala befolkningen av patienter som är berättigade till medicinen. När det gäller studien är nollhypotesen att populationsfrekvensen av fetma bland patienter på medicinen är lika med den totala fetma bland alla patienter som är berättigade till medicinen, det vill säga 25%., Ett one-tailed p-värde kan användas om det finns anledning att tro att en effekt skulle uppstå i endast en riktning (till exempel kan det finnas anledning att tro att medicinen skulle öka viktökning men inte minska den), medan ett två-tailed p-värde bör användas i alla andra fall. Vid användning av en symmetrisk fördelning, såsom normalfördelningen, är tvåtailed p-värden helt enkelt dubbelt så mycket som det entailed p-värdet.
Antag igen att ett prov på 30 patienter på medicinen innehåller 12 överviktiga individer. Med ett one-tailed test är vårt p-värde 0,0216 (med binomialfördelningen)., Således kan vi säga att vår observerade hastighet på 40% skiljer sig avsevärt från den hypotetiska hastigheten på 25% vid en signifikansnivå på 0,05. I en annan mening är 95% konfidensintervallet för den observerade andelen 25,6% till 61.07%. Konfidensintervall motsvarar två-tailed test, där ett två-tailed test avvisas om och endast om konfidensintervallet inte innehåller värdet associerat med nollhypotesen (i detta fall 25%).
om ett beräknat p-värde är litet är det troligt att befolkningen inte är strukturerad som ursprungligen angavs i nollhypotesen., Om vi får ett lågt P-värde har vi bevis för att det fanns någon effekt eller orsak till den observerade skillnaden – medicinen, i det här fallet. Ett tröskelvärde på 0,05 (eller 5%) används vanligtvis, där ett p-värde måste ligga under detta tröskelvärde för att dess motsvarande attribut ska vara statistiskt signifikant.
riskförhållanden
Risk, en annan term för Sannolikhet, är en annan grundläggande princip för statistisk analys. Sannolikhet är en jämförelse av att observera en specifik händelse som uppstår som ett resultat av de totala unika resultaten., Ett mynt flip är ett trivialt exempel: risken att observera ett huvuden är ½ eller 50%, som av alla möjliga unika försök (en flip resulterar i huvuden eller en flip resulterar i svansar), endast en är händelsen av intresse (huvuden).
användning av endast risk möjliggör förutsägelser om en enda population. Till exempel, om man tittar på fetma i den amerikanska befolkningen, rapporterade CDC att 42,4% av vuxna var överviktiga i 2017-2018. Så risken för att en individ i USA är överviktig är cirka 42,4%. De flesta studier tittar dock på effekten av ett specifikt ingrepp eller annat föremål (såsom dödlighet) på en annan., Tidigare antog vi att fetma hos berättigade patienter var 25%, men här kommer vi att använda 42,4% i samband med den amerikanska vuxna befolkningen. Antag att vi observerar en risk på 25% i ett slumpmässigt urval av patienter på medicinen också. För att konceptualisera effekten av Medicinen på fetma, skulle ett logiskt nästa steg vara att dela risken för fetma i den amerikanska befolkningen på medicinen med risken för fetma i den amerikanska befolkningen, vilket resulterar i ett riskförhållande på 0,590.,
denna beräkning – ett förhållande mellan två risker – är vad som menas med den eponymous risk ratio (rr) statistik, även känd som relativ risk. Det gör att ett visst antal kan ges för hur mycket mer risk en individ i en kategori bär jämfört med en individ i en annan kategori. I exemplet bär en individ som tar medicinen 0.59 gånger så mycket risk som en vuxen från den allmänna amerikanska befolkningen., Vi har dock antagit att befolkningen som är berättigad till medicinen hade en fetma på 25% – kanske bara en grupp unga vuxna, som kan vara hälsosammare i genomsnitt, är berättigade att ta medicinen. Vid undersökning av läkemedlets effekt på fetma är detta den andel som ska användas som nollhypotesen. Om vi observerar en fetma på medicinen på 40%, med ett p-värde mindre än signifikansnivån på 0,05, är detta bevis på att medicinen ökar risken för fetma (med en RR, i detta scenario, av 1,6)., Som sådan är det viktigt att noggrant välja nollhypotesen för att göra relevanta statistiska förutsägelser.
med RR betyder ett resultat av 1 att båda grupperna har samma riskbelopp, medan resultaten inte är lika med 1 indikerar att en grupp hade mer risk än en annan, en risk som antas bero på det ingripande som undersöktes av studien (formellt antagandet om orsaksriktning).
för att illustrera tittar vi på resultaten av en 2009-studie publicerad i Journal of Stroke och cerebrovaskulära sjukdomar., Studien rapporterar att patienter med ett långvarigt elektrokardiografiskt QTc-intervall var mer benägna att dö inom 90 dagar jämfört med patienter utan ett långvarigt intervall (relativ risk =2, 5; 95% konfidensintervall 1, 5-4, 1) . Att ha ett konfidensintervall mellan 1, 5 och 4, 1 för riskförhållandet indikerar att patienter med ett långvarigt QTc-intervall var 1, 5-4, 1 gånger större risk att dö i 90 dagar än patienter utan ett långvarigt QTc-intervall.,
ett andra exempel – i ett landmärke papper som visar att blodtryckskurvan vid akut ischemisk stroke är U-formad snarare än J-formad , fann undersökarna att RR ökade nästan tvåfaldigt hos patienter med genomsnittligt arteriellt blodtryck (karta) >140 mmHg eller <100 mmHg (RR=1,8, 95% CI 1,1-2,9, p=0,027). Att ha en CI på 1, 1-2, 9 för RR innebär att patienter med en karta utanför intervallet 100-140 mmHg var 1, 1-2, 9 gånger mer benägna att dö än de som hade första karta inom detta intervall.,
för ett annat exempel fann en 2018-studie om Australian naval recruits att de med prefabricerade ortoser (en typ av fotstöd) hade en 20.3% risk att drabbas av minst en negativ effekt, medan de utan risk hade 12.4% . Ett riskförhållande här ges av 0.203 / 0.124 eller 1.63, vilket tyder på att rekryter med fotortos Bar 1.63 gånger risken för att få någon negativ konsekvens (t.ex. fotblåsare, smärta etc.) än de utan. I samma studie rapporteras emellertid ett konfidensintervall på 95% för riskkvoten på 0, 96 till 2, 76, med ett p-värde på 0, 068., Om man tittar på konfidensintervallet innehåller 95% rapporterat intervall (den allmänt accepterade standarden) värden under 1, 1 och värden över 1. Kom ihåg att alla värden är lika sannolikt att vara befolkningsstatistiken, med 95% förtroende, finns det inget sätt att utesluta möjligheten att fotortoser inte har någon effekt, har en betydande fördel eller har en betydande nackdel. Dessutom är p-värdet större än standarden på 0,05, därför ger dessa data inga signifikanta bevis på fotortoser som har någon konsekvent effekt på biverkningar som blåsor och smärta., Som tidigare nämnts är detta ingen slump – om de beräknas med samma eller liknande metoder och p-värdet är tvåtailed, kommer konfidensintervall och p-värden att rapportera samma resultat.
när de används korrekt är riskkvoterna en kraftfull statistik som möjliggör en uppskattning i en population av riskförändringen som en population bär över en annan., De är ganska lätta att förstå (värdet är hur många gånger risken en grupp bär över en annan), och med antagandet om orsaksriktning, visar snabbt om en intervention (eller annan testad variabel) har en effekt på resultaten.
det finns dock begränsningar. För det första kan RRs inte tillämpas i samtliga fall. Eftersom risken i ett urval är en uppskattning av risken i en population måste urvalet vara rimligt representativt för populationen. Som sådan kan fallkontrollstudier, på grund av det faktum att utfallsförhållandena kontrolleras, inte ha någon rapporterad riskkvot., För det andra, som med all den statistik som diskuteras häri, är RR en relativ åtgärd som ger information om risken i en grupp i förhållande till en annan. Problemet här är att en studie där två grupper hade en risk på 0,2% och 0,1% bär samma RR, 2, som en där två grupper hade en risk på 90% och 45%. Även om det i båda fallen är sant att de med interventionen var dubbelt så risk, motsvarar detta endast 0,1% mer risk i ett fall medan 45% mer risk i ett annat fall., Således, rapportering endast RR överdriver effekten i första hand, medan potentiellt även minimera effekten (eller åtminstone dekontextualisera det) i andra instans.
Oddskvoter
medan riskrapporterar antalet händelser av intresse i förhållande till det totala antalet försök, rapporterar oddsen antalet händelser av intresse i förhållande till antalet händelser som inte är av intresse. Anges annorlunda, rapporterar det antalet händelser till icke-händelser., Medan risken, som tidigare bestämts, att vända ett mynt för att vara huvuden är 1: 2 eller 50%, är oddsen att vända ett mynt för att vara huvuden 1:1, eftersom det finns ett önskat resultat (händelse) och ett oönskat resultat (icke-händelsevis) (Figur 1).
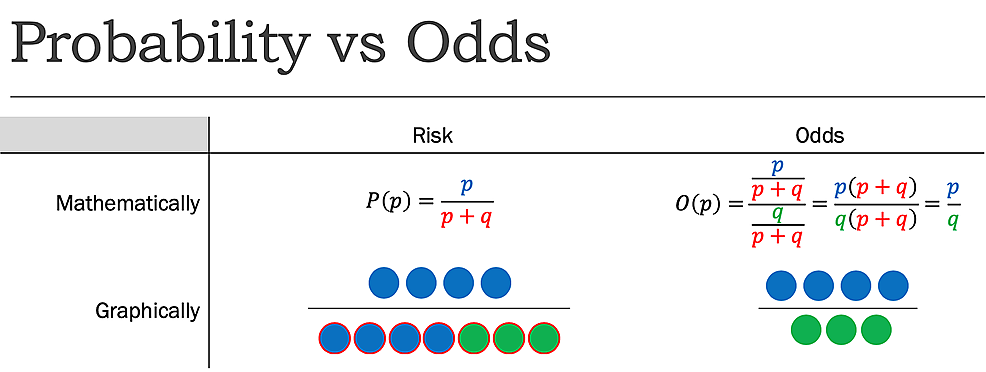
Figure1:Probability (P) vs. Odds (O) där p=probability of success and q=probability of failure
precis som med RR, där förhållandet mellan två risker togs för två separata grupper, kan ett förhållande mellan två odds tas för två separata grupper till producera ett oddsförhållande (eller)., I stället för att rapportera hur många gånger risken en grupp bär i förhållande till den andra, rapporterar den hur många gånger oddsen en grupp bär till den andra.
för de flesta är detta en svårare statistik att förstå. Risk är ofta ett mer intuitivt koncept än odds, och därmed är förståelse av relativa risker ofta att föredra för att förstå relativa odds. Men, eller inte lider av samma orsakssamband antagande begränsningar som RR, vilket gör det mer allmänt tillämplig.,
oddsen är till exempel en symmetrisk åtgärd, vilket innebär att även om risk endast undersöker resultat som ges insatser, kan oddsen också undersöka insatser som ges resultat. Således kan en studie konstrueras där, snarare än att välja försöksgrupper och mäta resultat, resultat kan väljas och andra faktorer kan analyseras. Följande är ett exempel på en fallkontrollstudie, en situation där RR inte kan användas men eller kan.
en fallkontrollstudie 2019 visar ett bra exempel., Försök att hitta potentiell korrelation mellan en hepatit A-virus (HAV) infektion framträdande i Kanada och vissa orsakande faktor, en studie konstruerades baserat på resultatet (med andra ord, individer kategoriserades baserat på deras HAV status, som ”intervention”, eller orsakssamband, var okänd). Studien tittade på dem med HAV och de utan och vilka livsmedel de hade ätit före HAV-infektion . Från detta konstruerades flera oddsförhållanden som jämförde ett visst livsmedelsartikel med HAV-status., Till exempel fann uppgifterna att bland de personer som hade exponering för räkor/räkor var åtta positiva för HAV medan sju inte var, medan för de utan exponering två var positiva för HAV medan 29 inte var. Ett oddsförhållande tas av (8:7)/(2:29) vilket motsvarar ungefär 16,6. Undersökningsdata rapporterade en eller 15.75, med den lilla diskrepansen som sannolikt härrör från eventuella justeringar före beräkningen för förvirrande variabler som inte diskuterades i dokumentet. Ett p-värde på 0,01 rapporterades, vilket gav statistiska bevis för detta eller är signifikant.,
detta kan tolkas på två lika sätt. För det första är oddsen för räkor/räkor för dem med HAV 15.75 gånger högre än för dem utan. Likvärdigt är oddsen för HAV-posiitve mot HAV-negative 15.75 gånger högre för dem som utsätts för räkor än för dem som inte exponeras.
totalt sett, eller ger ett mått på styrkan i samband mellan två variabler på en skala av 1 är ingen förening, över 1 är en positiv förening, och under 1 är en negativ förening., Även om de två föregående tolkningarna är korrekta är de inte så direkt begripliga som en RR skulle ha varit, om det hade varit möjligt att bestämma en. En alternativ tolkning är att det finns en stark positiv korrelation mellan räkor / räkor exponering och HAV.
på grund av detta är det i vissa specifika fall lämpligt att approximera RR med eller. I sådana fall måste det sällsynta sjukdomsantagandet hålla. Det vill säga en sjukdom måste vara mycket sällsynt inom en befolkning., I detta fall, risken för sjukdomen inom befolkningen (p/(p+q)) närmar sig oddsen för sjukdomen inom befolkningen (p / q) som p blir obetydligt liten i förhållande till q. således, rr och eller konvergera som befolkningen blir större. Men om detta antagande misslyckas blir skillnaden alltmer överdriven. Matematiskt ökar minskande p i P + q-försök q för att upprätthålla samma totala försök. Med risk ändras endast täljaren, medan med odds ändras både täljaren och nämnaren i motsatta riktningar., Som ett resultat, för de fall där RR och eller är båda under 1, den eller kommer att underskatta RR, medan för de fall där båda är över 1, den eller kommer att överskatta RR.
felaktig rapportering av eller som RR, då, kan ofta överdriva data. Det är viktigt att komma ihåg att eller är en relativ åtgärd precis som RR, och därmed ibland en stor eller kan motsvara en liten skillnad mellan odds.
för den mest trofasta rapporteringen, då, eller bör inte presenteras som en RR, och bör endast presenteras som en approximation av RR om den sällsynta sjukdomen antagandet rimligen kan hålla., Om möjligt ska en RR alltid rapporteras.
Hazard ratio
både RR och eller avser interventioner och resultat, vilket rapporterar över en hel studieperiod. En liknande men tydlig åtgärd, riskkvoten (HR), gäller dock förändringstakten (Tabell 1).
| RR | eller | HR | |
| mål | bestäm förhållandet i riskstatus baserat på någon variabel. | Bestäm sambandet mellan två variabler., | Bestäm hur en grupp ändras i förhållande till en annan. |
| använd | berättar hur en intervention förändrar riskerna. | berättar om det finns en koppling mellan en intervention och risk; uppskattar hur denna förening gäller. | berättar hur en intervention ändrar graden av att uppleva en händelse. |
| begränsningar | gäller endast om studiedesignen är representativ för befolkningen. Kan inte användas vid fallkontrollstudier. | kan i allmänhet tillämpas överallt, men inte alltid en användbar statistik själv. Överdriver risker., | för att normalt vara användbart bör förändringstakten inom två grupper vara relativt konsekvent. |
| tidslinje | Static – överväger inte priser. Sammanfattar en övergripande studie. | Static-anser inte priser. Sammanfattar en övergripande studie. | baserat på priser. Ger information om hur en studie fortskrider över tiden. |
Table1: Relative risk (RR) vs. Odds Ratio (or) vs., Hazard Ratio (HR)
timmar är i kombination med survivorship kurvor, som visar den tidsmässiga utvecklingen av någon händelse inom en grupp, oavsett om händelsen är död, eller upphandlande en sjukdom. I en överlevnadskurva motsvarar den vertikala axeln händelsen av intresse och den horisontella axeln motsvarar tiden. Risken för händelsen motsvarar sedan grafens lutning eller händelserna per tid.
ett riskförhållande är helt enkelt en jämförelse av två faror., Det kan visa hur snabbt två överlevnadskurvor avviker genom jämförelse av kurvornas sluttningar. En HR på 1 indikerar ingen avvikelse – inom båda kurvorna var sannolikheten för händelsen lika sannolikt vid varje given tidpunkt. En HR som inte är lika med 1 indikerar att två händelser inte inträffar i samma takt, och risken för en individ i en grupp är annorlunda än risken för en individ i en annan vid ett visst tidsintervall.
ett viktigt antagande att HRs gör är proportionella satser antagande., För att rapportera ett enstaka farokvot måste det antas att de två farokraterna är konstanta. Om grafens lutning ska ändras kommer förhållandet också att förändras över tiden och kommer därför inte att tillämpas som en jämförelse av sannolikheten vid en viss tidpunkt.
överväga studien av ett nytt kemoterapeutiskt medel som syftar till att förlänga livslängden hos patienter med en specifik cancer. I både interventionen och kontrollgruppen hade 25% dött vid vecka 40., Eftersom båda grupperna minskade från 100% överlevnad till 75% överlevnad under 40-veckorsperioden, skulle riskfrekvensen vara lika med och därmed riskfrekvensen lika med 1. Detta tyder på att en individ som tar emot läkemedlet är lika sannolikt att dö som en som inte tar emot läkemedlet när som helst.
det är dock möjligt att i interventionsgruppen dog alla 25% mellan veckorna sex till 10, medan för kontrollgruppen dog alla 25% inom veckor en till sex. I detta fall skulle jämföra medianer visa en högre livslängd för dem på drogen trots HR inte visar någon skillnad., I det här fallet misslyckas antagandet om proportionella faror, eftersom farofrekvensen förändras (ganska dramatiskt) över tiden. I sådana fall är HR inte tillämpligt.
eftersom det ibland är svårt att avgöra om antagandet om proportionella risker är rimligt, och eftersom man tar en HR-strips den ursprungliga mätningen (farofrekvenser) av tidsenheten, är det vanligt att rapportera HR i samband med mediantider.,
i en studie som utvärderade prognostisk prestanda för Rapid Emergency Medicine Score (REMS) och Worthing Physiological poängsystem (WPS) fann undersökarna att risken för 30-dagars mortalitet ökade med 30% för varje ytterligare REMS-enhet (HR: 1.28; 95% konfidensintervall (CI): 1.23-1.34) och med 60% för varje ytterligare WPS-enhet (HR: 1.6; 95% CI: 1.5-1.7). I det här fallet förändrades inte dödsgraden, utan snarare poängsystemet för att förutsäga det gjorde, så HR kan användas. Med ett konfidensintervall mellan 1,5 och 1.,7 för riskförhållandet för WPSS indikerar att dödlighetskurvan för dem med högre WPS minskar i snabbare takt (ca 1,5-1,7 gånger). Eftersom den låga änden av intervallet fortfarande är över 1, är vi övertygade om att den verkliga dödsrisken inom 30 dagar är högre för gruppen med högre WPS .
i en 2018-studie om binge-dricks bland individer med vissa riskfaktorer konstruerades en överlevnadskurva som plottade graden av att uppnå binge-dricks för kontroller, de med familjehistoria, manligt kön, de med hög impulsivitet och de med högre respons på alkohol., För män och de med familjehistoria rapporterades statistiskt signifikanta bevis för en högre grad av att uppnå binge-dricks (en HR på 1.74 för män och 1.04 för de med familjehistoria) . För dem med hög impulsivitet, även om HR var 1.17, varierade 95% konfidensintervall från 1.00 till 1.37. Således, till en 95% konfidensnivå, är det omöjligt att utesluta att HR var 1,00.,
på grund av den överdrift som finns är det viktigt att undvika att representera ORs som RRs, och på samma sätt är det viktigt att erkänna att en rapporterad eller sällan ger en bra approximation av relativa risker utan helt enkelt ger ett mått på korrelation.
på grund av sin förmåga att göra fasta slutsatser och förståelighet bör RR rapporteras om möjligt, men i de fall där dess orsakssambandsantagande bryts (t.ex. fallkontrollstudier och logistisk regression) eller kan användas.,
timmar används med överlevnadskurvor och antar att farofrekvensen är lika med tiden. Även om det är lämpligt att jämföra två satser, bör de rapporteras med mediantider för att motivera antagandet om proportionella risker.
slutligen, oavsett värdet av HR / RR / eller statistik, bör en tolkning göras först efter att ha bestämt om resultatet ger statistiskt signifikanta bevis mot en slutsats (som bestäms av p-värde eller konfidensintervall)., Att komma ihåg dessa principer och ramverket för HR/RR/eller minimerar förvrängning och förhindrar att man drar felaktiga slutsatser från resultaten av en publicerad studie om olika prover. Figur 2 sammanfattar korrekt och felaktig användning av dessa olika riskförhållanden.
