Intervalli di confidenza e valori p
Per intrattenere qualsiasi discussione sull’analisi statistica, è importante prima comprendere il concetto di statistica demografica. Chiaramente, le statistiche sulla popolazione sono i valori di qualsiasi misura all’interno della popolazione di interesse, e stimarli è l’obiettivo della maggior parte degli studi ., Ad esempio, in uno studio che esamina i tassi di obesità per i pazienti trattati con un determinato farmaco, la statistica della popolazione potrebbe essere il tasso medio di obesità per tutti i pazienti trattati con il farmaco.
Tuttavia, l’identificazione di questo valore richiederebbe dati per ogni singolo individuo che rientra in questa categoria, il che non è pratico. Invece, è possibile raccogliere un campione randomizzato, da cui è possibile ottenere statistiche di esempio. Queste statistiche di esempio servono come stime delle corrispondenti statistiche sulla popolazione e consentono a un ricercatore di trarre conclusioni su una popolazione di interesse.,
Esiste una limitazione significativa in quanto questi campioni costruiti devono essere rappresentativi della popolazione più ampia di interesse. Mentre ci sono molti passi che possono essere presi per ridurre questa limitazione, a volte i suoi effetti (il cosiddetto bias di campionamento ) vanno oltre il controllo del ricercatore. Inoltre, anche in una situazione teorica senza pregiudizi di campionamento, la randomizzazione potrebbe risultare in un campione travisato. Nell’esempio precedente, supponiamo che il tasso di obesità della popolazione tra tutti gli adulti ammissibili per il farmaco fosse del 25%., In un semplice campione casuale di 30 pazienti di questa popolazione, c’è una probabilità del 19,7% che almeno 10 pazienti siano obesi, con un conseguente tasso di obesità del campione del 33,3% o anche superiore. Anche se non esiste alcuna relazione tra il farmaco e i tassi di obesità, è ancora possibile incontrare un tasso che sembra essere diverso dal tasso complessivo di obesità, che si è verificato attraverso la casualità nel campionamento da solo. Questo effetto è la ragione per la segnalazione di intervalli di confidenza e valori p nella ricerca clinica.
Gli intervalli di confidenza sono intervalli in cui la statistica della popolazione potrebbe trovarsi., Sono costruiti sulla base della statistica del campione e di alcune caratteristiche del campione che misurano la probabilità che sia rappresentativo e sono segnalati a una certa soglia . Un intervallo di confidenza del 95% è un intervallo costruito in modo tale che, in media, il 95% dei campioni casuali conterrebbe la statistica della popolazione vera entro il loro intervallo di confidenza del 95%. Pertanto, una soglia per risultati significativi è spesso presa come 95%, con la consapevolezza che tutti i valori all’interno dell’intervallo riportato sono ugualmente validi come la possibile statistica della popolazione.,
Il valore p riporta informazioni simili in modo diverso. Piuttosto che costruire un intervallo attorno a una statistica del campione, un valore p riporta la probabilità che la statistica del campione sia stata prodotta dal campionamento casuale di una popolazione, dato un insieme di ipotesi sulla popolazione, denominata “ipotesi nulla” ., Prendendo di nuovo lo studio di esempio sui tassi di obesità, il tasso di obesità tra il campione (un campione di pazienti trattati con il farmaco) potrebbe essere riportato insieme a un valore p che determina la possibilità che tale tasso possa essere prodotto dal campionamento casuale della popolazione complessiva di pazienti eleggibili per il farmaco. Nel caso dello studio, l’ipotesi nulla è che il tasso di popolazione di obesità tra i pazienti con il farmaco sia uguale al tasso complessivo di obesità tra tutti i pazienti idonei al farmaco, cioè il 25%., Un valore p a una coda può essere utilizzato se c’è motivo di credere che un effetto si verificherebbe in una sola direzione (ad esempio, potrebbe esserci motivo di credere che il farmaco aumenterebbe l’aumento di peso ma non lo diminuirebbe), mentre un valore p a due code dovrebbe essere usato in tutti gli altri casi. Quando si utilizza una distribuzione simmetrica, come la distribuzione normale, i valori p a due code sono semplicemente il doppio del valore p a una coda.
Supponiamo ancora una volta che un campione di 30 pazienti sul farmaco contiene 12 individui obesi. Con un test a una coda, il nostro valore p è 0.0216 (usando la distribuzione binomiale)., Quindi, possiamo dire che il nostro tasso osservato del 40% è significativamente diverso dal tasso ipotizzato del 25% a un livello di significatività di 0,05. In un altro senso, l’intervallo di confidenza del 95% per la proporzione osservata è dal 25,6% al 61,07%. Gli intervalli di confidenza corrispondono ai test a due code, dove un test a due code viene rifiutato se e solo se l’intervallo di confidenza non contiene il valore associato all’ipotesi nulla (in questo caso, 25%).
Se un valore p calcolato è piccolo, è probabile che la popolazione non sia strutturata come originariamente indicato nell’ipotesi nulla., Se otteniamo un basso valore p, abbiamo prove che c’è stato qualche effetto o motivo per la differenza osservata – il farmaco, in questo caso. In genere viene utilizzata una soglia di 0,05 (o 5%), con un valore p che deve essere inferiore a questa soglia affinché il suo attributo corrispondente sia statisticamente significativo.
Rapporti di rischio
Il rischio, un altro termine per probabilità, è un altro principio fondamentale dell’analisi statistica. La probabilità è un confronto tra l’osservazione di un evento specifico che si verifica come risultato dei risultati unici totali., Un coin flip è un esempio banale: il rischio di osservare una testa è ½ o 50%, come di tutte le possibili prove uniche (un flip con conseguente testa o un flip con conseguente croce), solo uno è l’evento di interesse (teste).
Utilizzando solo il rischio consente previsioni su una singola popolazione. Ad esempio, guardando i tassi di obesità all’interno della popolazione statunitense, il CDC ha riferito che 42.4% degli adulti era obeso in 2017-2018. Quindi, il rischio che un individuo negli Stati Uniti sia obeso è di circa il 42,4% . Tuttavia, la maggior parte degli studi esamina l’effetto di un intervento specifico o di un altro elemento (come la mortalità) su un altro., In precedenza, abbiamo supposto che il tasso di obesità dei pazienti eleggibili fosse del 25%, ma qui useremo il 42,4% associato alla popolazione adulta degli Stati Uniti. Supponiamo di osservare un rischio del 25% in un campione casuale di pazienti con il farmaco. Per concettualizzare l’effetto del farmaco sull’obesità, un passo successivo logico sarebbe dividere il rischio di obesità nella popolazione degli Stati Uniti sul farmaco con il rischio di obesità nella popolazione degli Stati Uniti, che si traduce in un rapporto di rischio di 0.590.,
Questo calcolo – un rapporto di due rischi – è ciò che si intende con l’omonima statistica risk ratio (RR), nota anche come rischio relativo. Consente di fornire un numero specifico per quanto più rischio un individuo in una categoria sopporta rispetto a un individuo in un’altra categoria. Nell’esempio, un individuo che prende il farmaco porta 0,59 volte più rischio di un adulto dalla popolazione generale degli Stati Uniti., Tuttavia, abbiamo ipotizzato che la popolazione ammissibile per il farmaco aveva un tasso di obesità del 25% – forse solo un gruppo di giovani adulti, che possono essere più sani in media, sono ammissibili a prendere il farmaco. Quando si studia l’effetto del farmaco sull’obesità, questa è la proporzione che dovrebbe essere usata come ipotesi nulla. Se osserviamo un tasso di obesità sul farmaco del 40%, con un valore p inferiore al livello di significatività di 0,05, questa è la prova che il farmaco aumenta il rischio di obesità (con un RR, in questo scenario, di 1,6)., Come tale, è importante scegliere con attenzione l’ipotesi nulla per fare previsioni statistiche rilevanti.
Con RR, un risultato di 1 significa che entrambi i gruppi hanno la stessa quantità di rischio, mentre risultati non uguali a 1 indicano che un gruppo ha più rischio di un altro, un rischio che si presume sia dovuto all’intervento esaminato dallo studio (formalmente, l’assunzione della direzione causale).
Per illustrare, guardiamo i risultati di uno studio del 2009 pubblicato sul Journal of Stroke and Cerebrovascular Diseases., Lo studio riporta che i pazienti con intervallo QTc elettrocardiografico prolungato avevano maggiori probabilità di morire entro 90 giorni rispetto ai pazienti senza intervallo prolungato (rischio relativo =2,5; intervallo di confidenza al 95% 1,5-4,1) . Avere un intervallo di confidenza tra 1,5 e 4,1 per il rapporto di rischio indica che i pazienti con un intervallo QTc prolungato avevano 1,5-4,1 volte più probabilità di morire in 90 giorni rispetto a quelli senza un intervallo QTc prolungato.,
Un secondo esempio – in un punto di riferimento della carta dimostrando che la pressione del sangue curva nell’ictus ischemico acuto è a forma di U, piuttosto che a forma di J , i ricercatori hanno scoperto che la RR è aumentato di quasi due volte in pazienti con pressione arteriosa media (MAP) >140 mmHg o <100 mmHg (RR=1.8, 95% CI 1.1-2.9, p=0,027). Avere un IC di 1,1-2,9 per la RR significa che i pazienti con una MAPPA al di fuori dell’intervallo di 100-140 mmHg avevano 1,1-2,9 volte più probabilità di morire rispetto a quelli che avevano una MAPPA iniziale all’interno di questo intervallo.,
Per un altro esempio, uno studio del 2018 sulle reclute navali australiane ha rilevato che quelle con ortesi prefabbricate (un tipo di supporto del piede) avevano un rischio del 20,3% di subire almeno un effetto negativo, mentre quelle senza avevano un rischio del 12,4% . Un rapporto di rischio qui è dato da 0,203 / 0,124, o 1,63, suggerendo che le reclute con ortesi del piede portavano 1,63 volte il rischio di avere qualche conseguenza avversa (ad esempio blister del piede, dolore, ecc.) di quelli senza. Tuttavia, lo stesso studio riporta un intervallo di confidenza del 95% per il rapporto di rischio da 0,96 a 2,76, con un valore p di 0,068., Guardando l’intervallo di confidenza, l’intervallo riportato al 95% (lo standard comunemente accettato) include valori inferiori a 1, 1 e valori superiori a 1. Ricordando che tutti i valori sono ugualmente probabili essere la statistica della popolazione, al 95% di fiducia, non c’è modo di escludere la possibilità che le ortesi del piede non abbiano alcun effetto, abbiano un beneficio significativo o abbiano un danno significativo. Inoltre, il valore p è maggiore dello standard di 0,05, pertanto questi dati non forniscono prove significative di ortesi del piede che hanno effetti coerenti su eventi avversi come vesciche e dolore., Come affermato in precedenza, questo non è un caso: se vengono calcolati utilizzando lo stesso o metodi simili e il valore p è a due code, gli intervalli di confidenza e i valori p riportano gli stessi risultati.
Se utilizzati correttamente, i rapporti di rischio sono una potente statistica che consente una stima in una popolazione del cambiamento di rischio che una popolazione sopporta rispetto a un’altra., Sono abbastanza facili da capire (il valore è quante volte il rischio che un gruppo sopporta rispetto ad un altro) e, con l’assunzione della direzione causale, mostrano rapidamente se un intervento (o un’altra variabile testata) ha un effetto sui risultati.
Tuttavia, ci sono limitazioni. In primo luogo, le RRS non possono essere applicate in tutti i casi. Poiché il rischio in un campione è una stima del rischio in una popolazione, il campione deve essere ragionevolmente rappresentativo della popolazione. In quanto tali, gli studi caso-controllo, per semplice virtù del fatto che i rapporti dei risultati sono controllati, non possono avere un rapporto di rischio riportato., In secondo luogo, come per tutte le statistiche qui discusse, RR è una misura relativa, che fornisce informazioni sul rischio in un gruppo rispetto a un altro. Il problema è che uno studio in cui due gruppi avevano un rischio dello 0,2% e dello 0,1% porta lo stesso RR, 2, di uno in cui due gruppi avevano un rischio del 90% e del 45%. Anche se in entrambi i casi è vero che quelli con l’intervento erano a doppio rischio, ciò equivale a solo lo 0,1% in più di rischio in un caso, mentre il 45% in più di rischio in un altro caso., Pertanto, riportare solo l’RR esagera l’effetto in prima istanza, mentre potenzialmente riduce al minimo l’effetto (o almeno decontestualizzandolo) nella seconda istanza.
Odds ratio
Mentre risk riporta il numero di eventi di interesse in relazione al numero totale di prove, odds riporta il numero di eventi di interesse in relazione al numero di eventi non di interesse. Dichiarato in modo diverso, riporta il numero di eventi ai non eventi., Mentre il rischio, come determinato in precedenza, di lanciare una moneta per essere teste è 1:2 o 50%, le probabilità di lanciare una moneta per essere teste è 1:1, in quanto vi è un risultato desiderato (evento) e un risultato indesiderato (non evento) (Figura 1).
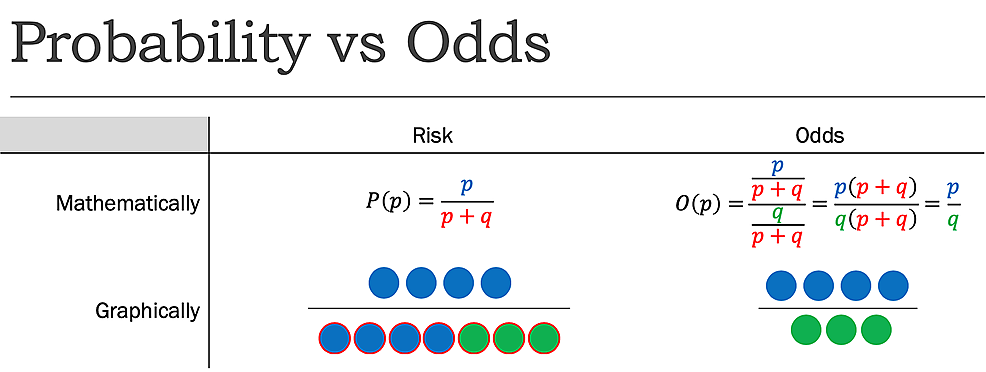
Figura 1:Probabilità (P) e di Probabilità (O) (p=probabilità di successo e q=probabilità di guasto
Proprio come con RR, dove il rapporto tra le due rischi è stato preso per due gruppi separati, con un rapporto di due probabilità può essere preso per due gruppi separati per produrre un odds ratio (or)., Invece di riportare quante volte il rischio un gruppo sopporta rispetto all’altro, riporta quante volte le probabilità un gruppo sopporta all’altro.
Per la maggior parte, questa è una statistica più difficile da capire. Il rischio è spesso un concetto più intuitivo delle probabilità, e quindi la comprensione dei rischi relativi è spesso preferita alla comprensione delle probabilità relative. Tuttavia, O non soffre delle stesse limitazioni di assunzione causale di RR, rendendolo più ampiamente applicabile.,
Ad esempio, le probabilità sono una misura simmetrica, il che significa che mentre il rischio esamina solo i risultati dati gli interventi, le probabilità possono anche esaminare gli interventi dati i risultati. Quindi, uno studio può essere costruito dove, piuttosto che scegliere gruppi di prova e misurare i risultati, i risultati possono essere scelti e altri fattori possono essere analizzati. Il seguente è un esempio di uno studio caso-controllo, una situazione in cui RR non può essere utilizzato ma O può.
Uno studio caso-controllo 2019 dimostra un buon esempio., Cercando di trovare una potenziale correlazione tra un’infezione da virus dell’epatite A (HAV) prominente in Canada e alcuni fattori causanti, uno studio è stato costruito sulla base del risultato (in altre parole, gli individui sono stati classificati in base al loro stato HAV, poiché l ‘ “intervento”, o evento causale, era sconosciuto). Lo studio ha esaminato quelli con HAV e quelli senza e quali alimenti avevano mangiato prima dell’infezione da HAV . Da questo, sono stati costruiti più rapporti di probabilità confrontando uno specifico prodotto alimentare con lo stato HAV., Ad esempio, i dati hanno rilevato che tra quei soggetti che avevano un’esposizione a gamberetti/gamberi, otto erano positivi per HAV mentre sette non lo erano, mentre per quelli senza esposizione due erano positivi per HAV mentre 29 non lo erano. Un odds ratio è preso da (8:7)/(2:29) che equivale a circa 16,6. I dati dello studio hanno riportato un OR di 15.75, con la piccola discrepanza probabilmente originata da eventuali aggiustamenti di pre-calcolo per le variabili confondenti che non sono state discusse nel documento. È stato riportato un valore p di 0,01, fornendo così prove statistiche per questo O per essere significativo.,
Questo può essere interpretato in due modi uguali. In primo luogo, le probabilità di esposizione di gamberetti/gamberi per quelli con HAV sono 15,75 volte superiori rispetto a quelli senza. Equivalentemente, le probabilità di HAV-positve contro HAV-negative sono 15,75 volte più alte per quelli esposti a gamberetti / gamberi che per quelli non esposti.
Nel complesso, O fornisce una misura della forza di associazione tra due variabili su una scala di 1 che non è un’associazione, sopra 1 è un’associazione positiva e sotto 1 è un’associazione negativa., Mentre le due interpretazioni precedenti sono corrette, non sono così direttamente comprensibili come sarebbe stato un RR, se fosse stato possibile determinarne uno. Un’interpretazione alternativa è che esiste una forte correlazione positiva tra l’esposizione di gamberetti/gamberi e l’HAV.
Per questo motivo, in alcuni casi specifici, è opportuno approssimare RR con OR. In questi casi, l’assunzione di malattie rare deve essere mantenuta. Cioè, una malattia deve essere estremamente rara all’interno di una popolazione., In questo caso, il rischio della malattia all’interno della popolazione (p/(p+q)) si avvicina alle probabilità della malattia all’interno della popolazione (p/q) poiché p diventa insignificante rispetto a q. Pertanto, l’RR e O convergono man mano che la popolazione diventa più grande. Tuttavia, se questa ipotesi fallisce, la differenza diventa sempre più esagerata. Matematicamente, negli studi p + q, la diminuzione di p aumenta q per mantenere gli stessi studi totali. Con il rischio, cambia solo il numeratore, mentre con le probabilità sia il numeratore che il denominatore cambiano in direzioni opposte., Di conseguenza, per i casi in cui RR e O sono entrambi inferiori a 1, l’OR sottovaluterà l’RR, mentre per i casi in cui entrambi sono superiori a 1, l’OR sovrastimerà l’RR.
La segnalazione errata dell’OR come RR, quindi, può spesso esagerare i dati. E ‘ importante ricordare che O è una misura relativa proprio come RR, e quindi a volte un grande O può corrispondere con una piccola differenza tra le probabilità.
Per la segnalazione più fedele, quindi, O non dovrebbe essere presentato come un RR, e dovrebbe essere presentato solo come un’approssimazione di RR se l’ipotesi di malattia rara può ragionevolmente reggere., Se possibile, un RR dovrebbe sempre essere segnalato.
Hazard ratio
Sia RR che O riguardano interventi e risultati, riportando quindi in un intero periodo di studio. Tuttavia, una misura simile ma distinta, l’hazard ratio (HR), riguarda i tassi di variazione (Tabella 1).
| RR | O | HR | |
| Obiettivo | Determinare relazione a condizioni di rischio sulla base di alcune variabili. | Determina l’associazione tra due variabili., | Determina come un gruppo cambia rispetto a un altro. |
| L’uso | ci dice come un intervento cambia i rischi. | Ci dice se esiste un’associazione tra un intervento e il rischio; stima come si applica questa associazione. | Ci dice come un intervento cambia il tasso di sperimentare un evento. |
| Limitazioni | Applicabili solo se il progetto di studio è rappresentativo della popolazione. Non può essere utilizzato su studi di caso-controllo. | Può generalmente essere applicato ovunque, ma non sempre una statistica utile in sé. Esagera i rischi., | Per essere tipicamente utile, il tasso di variazione all’interno di due gruppi dovrebbe essere relativamente coerente. |
| Timeline | Static – non considera i tassi. Riassume uno studio complessivo. | Static-non considera i tassi. Riassume uno studio complessivo. | In base alle tariffe. Fornisce informazioni sul modo in cui uno studio progredisce nel tempo. |
Tabello1: Rischio relativo (RR) vs. Odds Ratio (OR) vs., Hazard Ratio (HR)
Le ore sono in tandem con le curve di sopravvivenza, che mostrano la progressione temporale di un evento all’interno di un gruppo, sia che si tratti di morte o di contrarre una malattia. In una curva di sopravvivenza, l’asse verticale corrisponde all’evento di interesse e l’asse orizzontale corrisponde al tempo. Il pericolo dell’evento è quindi equivalente alla pendenza del grafico o agli eventi per volta.
Un hazard ratio è semplicemente un confronto di due pericoli., Può mostrare quanto velocemente due curve di sopravvivenza divergono attraverso il confronto delle pendenze delle curve. Un HR di 1 indica nessuna divergenza – all’interno di entrambe le curve, la probabilità dell’evento era ugualmente probabile in un dato momento. Un HR non uguale a 1 indica che due eventi non si verificano alla stessa velocità e il rischio di un individuo in un gruppo è diverso dal rischio di un individuo in un altro in un dato intervallo di tempo.
Un’ipotesi importante che HRs fa è l’assunzione di tassi proporzionali., Per segnalare un rapporto di rischio singolare, si deve presumere che i due tassi di pericolo siano costanti. Se la pendenza del grafico deve cambiare, anche il rapporto cambierà nel tempo e quindi non si applicherà come confronto di probabilità in un dato momento.
Considera lo studio di un nuovo agente chemioterapico che cerca di estendere l’aspettativa di vita dei pazienti con un tumore specifico. Sia nell’intervento che nel gruppo di controllo, 25% era morto entro la settimana 40., Poiché entrambi i gruppi sono diminuiti dalla sopravvivenza del 100% alla sopravvivenza del 75% durante il periodo di 40 settimane, i tassi di pericolo sarebbero uguali e quindi il tasso di pericolo uguale a 1. Ciò suggerisce che un individuo che riceve il farmaco è altrettanto probabile che muoia come uno che non riceve il farmaco in qualsiasi momento.
Tuttavia, è possibile che nel gruppo di intervento, tutto il 25% sia morto tra le settimane da sei a 10, mentre per il gruppo di controllo, tutto il 25% è morto entro settimane da uno a sei. In questo caso, confrontando mediane mostrerebbe una maggiore aspettativa di vita per quelli sul farmaco nonostante l’HR non mostra alcuna differenza., In questo caso, l’ipotesi di pericoli proporzionali fallisce, poiché i tassi di pericolo cambiano (abbastanza drammaticamente) nel tempo. In casi come questo, HR non è applicabile.
Poiché a volte è difficile determinare se l’ipotesi di rischi proporzionali si applica ragionevolmente e poiché l’assunzione di una HR toglie la misurazione originale (tassi di pericolo) dell’unità di tempo, è pratica comune riportare HR in combinazione con i tempi mediani.,
In uno studio di valutazione prognostico prestazioni della Rapida Medicina di Emergenza Punteggio (REMS) e il Worthing Fisiologico sistema di Punteggio (WPSS), i ricercatori hanno trovato che il rischio di mortalità a 30 giorni è stato aumentato del 30% per ogni ulteriore REMS unità (HR: 1.28; 95% intervallo di confidenza (CI): 1.23-1.34) e del 60% per ogni ulteriore WPSS unità (HR: 1.6; IC 95%: 1.5-1.7). In questo caso, il tasso di mortalità non è cambiato, ma piuttosto il sistema di punteggio per prevederlo, quindi l’HR può essere utilizzato. Avere un intervallo di confidenza tra 1,5 e 1.,7 per il rapporto pericoli WPSS indica che la curva di mortalità per quelli con un più alto WPS diminuisce ad un tasso più veloce (circa 1,5-1,7 volte). Poiché la fascia bassa dell’intervallo è ancora superiore a 1, siamo fiduciosi che il vero rischio di morte entro 30 giorni è più alto per il gruppo con WPS più alto .
In uno studio del 2018 sul binge drinking tra individui con determinati fattori di rischio, è stata costruita una curva di sopravvivenza che traccia il tasso di raggiungimento del binge drinking per i controlli, quelli con una storia familiare, sesso maschile, quelli con alta impulsività e quelli con una risposta più elevata all’alcol., Per gli uomini e quelli con una storia familiare, è stata riportata evidenza statisticamente significativa per un più alto tasso di raggiungimento del binge drinking (un’ora di 1,74 per gli uomini e 1,04 per quelli con una storia familiare) . Tuttavia, per quelli con alta impulsività, sebbene l’HR fosse 1.17, l’intervallo di confidenza del 95% variava da 1.00 a 1.37. Pertanto, a un livello di confidenza del 95%, è impossibile escludere che l’HR fosse 1.00.,
A causa dell’esagerazione presente, è importante evitare di rappresentare le RR come RR, e allo stesso modo, è importante riconoscere che una segnalazione O raramente fornisce una buona approssimazione dei rischi relativi, ma piuttosto fornisce semplicemente una misura di correlazione.
A causa della sua capacità di trarre conclusioni ferme e comprensibilità, RR dovrebbe essere segnalato se possibile, tuttavia nei casi in cui la sua assunzione di causalità viene violata (come studi di caso-controllo e regressione logistica), O può essere utilizzato.,
Le ore vengono utilizzate con le curve di sopravvivenza e presuppongono che i tassi di pericolo siano uguali nel tempo. Mentre utile per confrontare due tassi, dovrebbero essere segnalati con i tempi medi per giustificare l’ipotesi di rischi proporzionali.
Infine, indipendentemente dal valore dell’HR/RR/O della statistica, un’interpretazione dovrebbe essere fatta solo dopo aver determinato se il risultato fornisce prove statisticamente significative verso una conclusione (come determinato dal valore p o dall’intervallo di confidenza)., Ricordare questi principi e il quadro di HR / RR / O riduce al minimo le false dichiarazioni e impedisce di trarre conclusioni errate dai risultati di uno studio pubblicato riguardante vari campioni. La figura 2 riassume l’uso corretto e scorretto di questi vari indici di rischio.
