przedziały ufności i wartości p
w celu omówienia analizy statystycznej ważne jest, aby najpierw zrozumieć pojęcie statystyki populacji. Po prostu, statystyki populacji są wartościami każdej miary w obrębie populacji zainteresowania, a oszacowanie ich jest celem większości badań ., Na przykład, w badaniu oceniającym wskaźniki otyłości u pacjentów przyjmujących określone leki, statystyka populacji może być średnim wskaźnikiem otyłości dla wszystkich pacjentów przyjmujących leki.
jednak określenie tej wartości wymagałoby posiadania danych dla każdej osoby, która należy do tej kategorii, co jest niepraktyczne. Zamiast tego można zebrać randomizowaną próbkę, z której można uzyskać statystyki próbki. Te przykładowe statystyki służą jako szacunki odpowiednich statystyk populacji i pozwalają badaczowi na wyciągnięcie wniosków na temat zainteresowanej populacji.,
istnieje znaczące ograniczenie w tym, że te skonstruowane próbki muszą być reprezentatywne dla większej populacji zainteresowanej. Chociaż istnieje wiele kroków, które można podjąć w celu zmniejszenia tego ograniczenia, czasami jego skutki (tak zwane odchylenie próbkowania ) wykraczają poza kontrolę badacza. Dodatkowo, nawet w sytuacji teoretycznej bez odchylenia próbkowania, randomizacja może spowodować błędne próby. W poprzednim przykładzie załóżmy, że wskaźnik otyłości wśród wszystkich dorosłych kwalifikujących się do leczenia wynosił 25%., W prostej próbie losowej 30 pacjentów z tej populacji, istnieje 19,7% szansa, że co najmniej 10 pacjentów będzie otyłych, co powoduje odsetek otyłości próbki 33,3% lub nawet wyższy. Nawet jeśli nie ma związku między lekami a wskaźnikami otyłości, nadal można napotkać wskaźnik, który wydaje się być inny niż ogólny wskaźnik otyłości, który wystąpił przez losowość w samym pobieraniu próbek. Efekt ten jest powodem zgłaszania przedziałów ufności i wartości p w badaniach klinicznych.
przedziały ufności są przedziałami, w których statystyka populacji może leżeć., Są one skonstruowane w oparciu o statystykę próbki i pewne cechy próbki, które oceniają, jak prawdopodobne jest, aby być reprezentatywne i są zgłaszane do pewnego progu . 95% przedział ufności to przedział skonstruowany w taki sposób, że średnio 95% losowych próbek zawierałoby prawdziwą statystykę populacji w ich 95% przedział ufności. W związku z tym próg dla znaczących wyników jest często przyjmowany jako 95%, ze zrozumieniem, że wszystkie wartości w zgłaszanym zakresie są równie ważne, jak możliwa statystyka populacji.,
wartość p podaje podobne informacje w inny sposób. Zamiast konstruowania przedziału wokół statystyki próbki, wartość p zgłasza prawdopodobieństwo, że statystyka próbki została wyprodukowana z losowego pobierania próbek z populacji, biorąc pod uwagę zestaw założeń dotyczących populacji, dalej jako „hipoteza zerowa”., Biorąc przykładowe badanie na temat wskaźników otyłości ponownie, wskaźnik otyłości wśród próbki (Próbka pacjentów na lekach) może być zgłoszony wraz z wartością p określającą szansę, że taki wskaźnik może być wytworzony z losowo pobranej ogólnej populacji pacjentów kwalifikujących się do leczenia. W przypadku badania, hipoteza zerowa jest to, że wskaźnik populacji otyłości wśród pacjentów na leki jest równa ogólnej stopy otyłości wśród wszystkich pacjentów kwalifikujących się do leczenia, czyli 25%., Wartość p o jednym ogonie może być stosowana, jeśli istnieje powód, aby sądzić, że efekt wystąpi tylko w jednym kierunku (na przykład, może istnieć powód, aby sądzić, że lek zwiększy przyrost masy ciała, ale nie zmniejszy go), podczas gdy wartość p o dwóch ogonach powinna być stosowana we wszystkich innych przypadkach. Przy użyciu rozkładu symetrycznego, takiego jak rozkład normalny, wartości p o dwóch ogonach są po prostu dwa razy większe od wartości p o jednym ogonie.
Załóżmy ponownie, że próbka 30 pacjentów przyjmujących lek zawiera 12 otyłych osób. W teście jednostajnym nasza wartość p wynosi 0,0216 (przy zastosowaniu rozkładu dwumianowego)., Tak więc, możemy powiedzieć, że nasz obserwowany wskaźnik 40% znacznie różni się od hipotetycznego wskaźnika 25% na poziomie istotności 0,05. W innym sensie 95% przedział ufności dla obserwowanego odsetka wynosi 25,6% do 61,07%. Przedziały ufności odpowiadają testom dwuogoniastym, gdzie TEST dwuogoniastym jest odrzucany wtedy i tylko wtedy, gdy przedział ufności nie zawiera wartości związanej z hipotezą zerową (w tym przypadku 25%).
Jeśli obliczona wartość p jest mała, jest prawdopodobne, że populacja nie jest zorganizowana, jak pierwotnie stwierdzono w hipotezie zerowej., Jeśli uzyskamy niską wartość p, mamy dowody na to, że istniał jakiś efekt lub przyczyna zaobserwowanej różnicy-w tym przypadku lek. Zazwyczaj stosuje się próg 0,05 (lub 5%), przy czym wartość p musi być poniżej tego progu, aby odpowiadający jej atrybut był statystycznie istotny.
wskaźniki ryzyka
ryzyko, inny termin na Prawdopodobieństwo, to kolejna podstawowa zasada analizy statystycznej. Prawdopodobieństwo to porównanie obserwacji określonego zdarzenia zachodzącego w wyniku do całkowitych unikalnych wyników., Rzut monetą jest trywialnym przykładem: ryzyko zaobserwowania orła wynosi ½ lub 50%, ze wszystkich możliwych unikalnych prób (rzut w postaci orła lub rzut w postaci ogona), tylko jeden jest interesującym zdarzeniem (Orzeł).
wykorzystanie tylko ryzyka pozwala na przewidywania dotyczące pojedynczej populacji. Na przykład, patrząc na wskaźniki otyłości w populacji USA, CDC poinformował, że 42,4% dorosłych było otyłych w latach 2017-2018. Tak więc ryzyko otyłości osoby w USA wynosi około 42,4%. Jednak większość badań dotyczy wpływu określonej interwencji lub innego elementu (np. śmiertelności) na inny., Wcześniej przypuszczaliśmy, że wskaźnik otyłości kwalifikujących się pacjentów wynosił 25%, ale tutaj użyjemy 42,4% związanych z dorosłą populacją USA. Załóżmy, że obserwujemy ryzyko 25% w losowej próbie pacjentów przyjmujących lek. Aby pojąć wpływ leku na otyłość, logicznym następnym krokiem byłoby podzielenie ryzyka otyłości w populacji USA na leki z ryzykiem otyłości w populacji USA, co skutkuje współczynnikiem ryzyka 0,590.,
To obliczenie – stosunek dwóch ryzyk – jest tym, co oznacza tytułowy wskaźnik ryzyka (RR), znany również jako ryzyko względne. Pozwala to podać konkretny numer, o ile większe ryzyko ponosi osoba w jednej kategorii w porównaniu do osoby w innej kategorii. W przykładzie osoba przyjmująca lek ponosi 0,59 razy większe ryzyko niż osoba dorosła z ogólnej populacji USA., Jednak założyliśmy, że populacja kwalifikująca się do leczenia miała wskaźnik otyłości na poziomie 25% – być może tylko grupa młodych dorosłych, którzy mogą być zdrowsi Średnio, są uprawnieni do przyjmowania leków. Podczas badania wpływu leku na otyłość, jest to proporcja, która powinna być stosowana jako hipoteza zerowa. Jeśli zaobserwujemy wskaźnik otyłości na lekach wynoszący 40%, przy wartości p mniejszej niż poziom istotności 0,05, jest to dowód na to, że lek zwiększa ryzyko otyłości (przy RR, w tym scenariuszu, 1,6)., Jako takie, ważne jest, aby starannie wybrać hipotezę zerową do odpowiednich prognoz statystycznych.
w przypadku RR wynik 1 oznacza, że obie grupy mają taką samą wielkość ryzyka, podczas gdy wyniki nie równe 1 wskazują, że jedna grupa ponosi większe ryzyko niż inna, ryzyko, które zakłada się, że jest to spowodowane interwencją badaną w badaniu (formalnie założenie kierunku przyczynowego).
aby zilustrować wyniki badania z 2009 roku opublikowanego w Journal of Stroke and Cerebrovascular Diseases., W badaniu stwierdzono, że pacjenci z wydłużonym odstępem QTc w elektrokardiografii częściej umierali w ciągu 90 dni niż pacjenci bez wydłużonego odstępu (ryzyko względne =2, 5; 95% przedział ufności 1, 5-4, 1) . Przedział ufności między 1, 5 a 4, 1 dla wskaźnika ryzyka wskazuje, że pacjenci z wydłużonym odstępem QTc byli 1, 5-4, 1 razy bardziej narażeni na śmierć w ciągu 90 dni niż pacjenci bez wydłużonego odstępu QTc.,
drugi przykład – w przełomowym artykule wykazującym , że krzywa ciśnienia krwi w ostrym udarze niedokrwiennym ma kształt litery U, a nie litery J, badacze odkryli, że RR zwiększył się prawie dwukrotnie u pacjentów ze średnim ciśnieniem tętniczym (MAP)>140 mmHg Lub<100 mmHg (RR=1, 8, 95% CI 1, 1-2, 9, p=0, 027). CI 1,1 – 2,9 dla RR oznacza, że pacjenci z MAP poza zakresem 100-140 mmHg byli 1,1-2,9 razy bardziej narażeni na śmierć niż ci, którzy mieli początkową MAP w tym zakresie.,
dla innego przykładu, badanie 2018 na Australijskich rekrutów morskich wykazało, że osoby z prefabrykowanymi ortezami (rodzaj podparcia stopy) miały 20.3% ryzyko wystąpienia przynajmniej jednego niekorzystnego efektu, podczas gdy osoby bez miały ryzyko 12.4% . Współczynnik ryzyka podaje się tutaj o 0,203/0,124, czyli 1,63, co sugeruje, że Rekruci z ortezami stóp mieli 1,63 razy większe ryzyko wystąpienia jakichś niekorzystnych konsekwencji (np. pęcherze stóp, ból itp.) niż te bez. Jednak w tym samym badaniu stwierdzono 95% przedział ufności dla współczynnika ryzyka od 0,96 do 2,76, przy wartości p wynoszącej 0,068., Patrząc na przedział ufności, zgłaszany zakres 95% (powszechnie przyjęty standard) obejmuje wartości poniżej 1, 1 i wartości powyżej 1. Pamiętając, że wszystkie wartości są równie prawdopodobne w statystyce populacji, przy 95% pewności, nie ma sposobu, aby wykluczyć możliwość, że ortezy stóp nie mają wpływu, mają znaczącą korzyść lub mają znaczną szkodę. Ponadto wartość p jest większa niż norma 0,05, dlatego dane te nie dostarczają istotnych dowodów na to, że ortezy stóp mają stały wpływ na działania niepożądane, takie jak pęcherze i ból., Jak wspomniano wcześniej, nie jest to przypadek – jeśli są one obliczane przy użyciu tych samych lub podobnych metod, a wartość p jest dwuetapowa, przedziały ufności i wartości p będą przedstawiać te same wyniki.
w przypadku prawidłowego wykorzystania współczynniki ryzyka są potężną statystyką, która pozwala oszacować w populacji zmianę ryzyka, które jedna populacja ponosi nad inną., Są one dość łatwe do zrozumienia (wartość polega na tym, ile razy ryzyko ponosi jedna grupa nad inną), a przy założeniu kierunku przyczynowego, szybko pokazują, czy interwencja (lub inna badana zmienna) ma wpływ na wyniki.
istnieją jednak ograniczenia. Po pierwsze, RRs nie może być stosowany we wszystkich przypadkach. Ponieważ ryzyko w próbie jest oszacowaniem ryzyka w populacji, próba musi być racjonalnie reprezentatywna dla populacji. W związku z tym w badaniach przypadków kontrolnych, z racji tego, że wskaźniki wyników są kontrolowane, nie można podać wskaźnika ryzyka., Po drugie, podobnie jak w przypadku wszystkich omawianych tutaj statystyk, RR jest miarą względną, dostarczającą informacji o ryzyku w jednej grupie względem drugiej. Problem polega na tym, że badanie, w którym dwie grupy miały ryzyko 0,2% i 0,1%, nosi takie samo ryzyko RR, 2, Jak badanie, w którym dwie grupy miały ryzyko 90% i 45%. Chociaż w obu przypadkach prawdą jest, że osoby objęte interwencją były dwukrotnie narażone na ryzyko, oznacza to tylko 0,1% większe ryzyko w jednym przypadku, podczas gdy 45% większe ryzyko w innym przypadku., Tak więc raportowanie tylko RR wyolbrzymia efekt w pierwszej instancji, a potencjalnie nawet minimalizuje efekt (lub przynajmniej dekontekstualizuje go) w drugiej instancji.
wskaźniki kursów
podczas gdy ryzyko informuje o liczbie zdarzeń będących przedmiotem zainteresowania w stosunku do całkowitej liczby prób, kursy informują o liczbie zdarzeń będących przedmiotem zainteresowania w stosunku do liczby zdarzeń nie będących przedmiotem zainteresowania. Inaczej powiedziane, raportuje liczbę zdarzeń do nonevents., Podczas gdy ryzyko, jak określono wcześniej, rzucania monetą jako orzeł wynosi 1:2 lub 50%, szanse rzucania monetą jako orzeł wynosi 1: 1, ponieważ istnieje jeden pożądany wynik (Zdarzenie) i jeden niepożądany wynik (nonevent) (Rysunek 1).
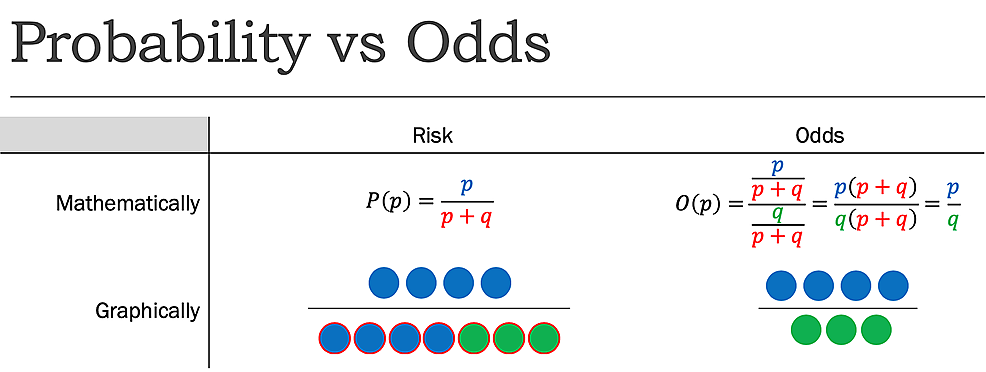
podobnie jak w przypadku RR, gdzie stosunek dwóch ryzyk został wzięty za dwie oddzielne grupy, stosunek dwóch kursów można przyjąć dla dwóch oddzielnych grup, aby uzyskać współczynnik kursów (lub)., Zamiast raportować, ile razy ryzyko ponosi jedna grupa w stosunku do drugiej, raportuje, ile razy kursy jedna grupa ponosi w stosunku do drugiej.
dla większości jest to statystyka trudniejsza do zrozumienia. Ryzyko jest często bardziej intuicyjnym pojęciem niż kursy, dlatego zrozumienie ryzyka względnego jest często preferowane niż zrozumienie kursów względnych. Jednak, lub nie cierpi z tych samych przyczynowych ograniczeń założenia jako RR, co szerzej stosowane.,
na przykład kursy są miarą symetryczną, co oznacza, że podczas gdy ryzyko analizuje tylko wyniki danej interwencji, kursy mogą również badać interwencje danej interwencji. W ten sposób można skonstruować badanie, w którym zamiast wybierać grupy próbne i mierzyć wyniki, można wybierać wyniki i analizować inne czynniki. Poniżej przedstawiono przykładowe badanie przypadku – sytuacji, w której RR nie może być stosowany, ale może.
dobrym przykładem jest badanie case-control Z 2019 roku., Próbując znaleźć potencjalną korelację między wirusowym zapaleniem wątroby typu A (HAV) widocznym w Kanadzie a pewnym czynnikiem powodującym, badanie zostało skonstruowane na podstawie wyniku (innymi słowy, osoby zostały sklasyfikowane na podstawie ich statusu HAV, jako” interwencja ” lub zdarzenie przyczynowe, było nieznane). W badaniu oceniano osoby z HAV i te Bez i jakie pokarmy spożywali przed zakażeniem HAV . Na tej podstawie skonstruowano wiele współczynników kursów porównujących konkretny produkt spożywczy ze statusem HAV., Na przykład, dane wykazały, że wśród osób, które miały ekspozycję na krewetki/krewetki, osiem było dodatnich dla HAV, podczas gdy siedem nie było, podczas gdy dla osób bez ekspozycji dwa były dodatnie dla HAV, podczas gdy 29 nie było. Stosunek kursów przyjmuje się przez (8:7)/(2:29) co odpowiada około 16.6. Dane z badania wykazały OR 15,75, z małą rozbieżnością prawdopodobnie pochodzącą z wszelkich korekt przed obliczeniami dla zmiennych mylących, które nie zostały omówione w artykule. Odnotowano wartość p wynoszącą 0,01, dostarczając tym samym dowodów statystycznych na to lub będąc znaczącym.,
można to interpretować na dwa równe sposoby. Po pierwsze, szanse na ekspozycję krewetek / krewetek dla osób z HAV są 15,75 razy wyższe niż dla osób bez. Równoważnie, szanse na HAV-posiitve w porównaniu z hav-ujemnym są 15,75 razy wyższe dla osób narażonych na krewetki / krewetki niż dla osób nie narażonych.
ogólnie, lub dostarcza miary siły związku między dwiema zmiennymi w skali 1 nie jest stowarzyszeniem, powyżej 1 jest asocjacją pozytywną, a poniżej 1 jest asocjacją negatywną., Podczas gdy poprzednie dwie interpretacje są poprawne, nie są one tak bezpośrednio zrozumiałe, jak byłoby RR, gdyby można było ustalić jedną. Alternatywną interpretacją jest to, że istnieje silna pozytywna korelacja między ekspozycją na krewetki/krewetki a HAV.
z tego powodu w niektórych szczególnych przypadkach właściwe jest przybliżenie RR do OR. W takich przypadkach, założenie rzadkiej choroby musi trzymać. Oznacza to, że choroba musi być niezwykle rzadka w populacji., W tym przypadku ryzyko choroby w populacji(p/(p+q)) zbliża się do szans choroby w populacji (P / q), ponieważ P staje się nieznacznie mały w stosunku do q. Tak więc RR i lub zbiegają się w miarę powiększania się populacji. Jeśli jednak to założenie nie powiedzie się, różnica staje się coraz bardziej przesadzona. Matematycznie, w badaniach p+q, zmniejszenie P zwiększa q, aby utrzymać te same całkowite próby. W przypadku ryzyka zmienia się tylko licznik, podczas gdy w przypadku kursów zarówno licznik, jak i mianownik zmieniają się w przeciwnych kierunkach., W związku z tym w przypadkach, w których RR i RR są niższe niż 1, RNO zaniży RR, podczas gdy w przypadkach, w których oba RR są wyższe niż 1, RNO zawyży RR.
błędne raportowanie OR jako RR może często wyolbrzymiać dane. Ważne jest, aby pamiętać, że Or jest miarą względną tak jak RR, a więc czasami duża lub może odpowiadać niewielkiej różnicy między kursami.
dla najwierniejszych raportów, a następnie, LUB NIE POWINNY być przedstawione jako RR, i powinny być przedstawione jako przybliżenie RR, jeśli założenie rzadkiej choroby może rozsądnie utrzymać., Jeśli to możliwe, należy zawsze zgłosić RR.
współczynniki ryzyka
zarówno RR, jak i OR dotyczą interwencji i wyników, a zatem sprawozdania z całego okresu badania. Jednakże podobny, ale odrębny środek, współczynnik ryzyka (HR), dotyczy tempa zmian (Tabela 1).
| RR | lub | HR | |
| cel | określenie zależności w statusie ryzyka na podstawie jakiejś zmiennej. | określa związek między dwiema zmiennymi., | określa, w jaki sposób jedna grupa zmienia się względem drugiej. |
| użyj | mówi nam, jak interwencja zmienia ryzyko. | mówi nam, czy istnieje związek między interwencją a ryzykiem; szacuje, jak to skojarzenie ma zastosowanie. | mówi nam, jak interwencja zmienia tempo przeżywania zdarzenia. |
| ograniczenia | mają zastosowanie tylko wtedy, gdy projekt badania jest reprezentatywny dla populacji. Nie może być stosowany w badaniach przypadków. | można na ogół stosować wszędzie, ale nie zawsze użyteczna sama statystyka. Wyolbrzymiają ryzyko., | aby zazwyczaj były użyteczne, tempo zmian w obrębie dwóch grup powinno być stosunkowo spójne. |
| Timeline | Static – nie uwzględnia stawek. Podsumowuje ogólne badanie. | Static-nie uwzględnia stawek. Podsumowuje ogólne badanie. | na podstawie stawek. Dostarcza informacji na temat sposobu badania postępuje w czasie. |
Table1: relative risk (RR) vs. Odds Ratio (OR) vs., Współczynnik ryzyka (HR)
HRs są połączone z krzywymi przetrwania, które pokazują czasowy postęp jakiegoś zdarzenia w grupie, niezależnie od tego, czy zdarzenie to jest śmiercią, czy zachorowaniem na chorobę. W krzywej przetrwania oś pionowa odpowiada zdarzeniu, a oś pozioma odpowiada czasowi. Ryzyko zdarzenia jest wówczas równoważne nachyleniu wykresu lub zdarzeniom na czas.
współczynnik ryzyka to po prostu porównanie dwóch zagrożeń., Może pokazać, jak szybko dwie krzywe przetrwania różnią się poprzez porównanie zboczy krzywych. Wartość HR równa 1 nie wskazuje na rozbieżność – w obrębie obu krzywych prawdopodobieństwo wystąpienia zdarzenia było jednakowo prawdopodobne w danym momencie. HR nie równa 1 oznacza, że dwa zdarzenia nie występują w jednakowym tempie, a ryzyko osoby w jednej grupie jest INNE niż ryzyko osoby w innej w danym przedziale czasowym.
ważnym założeniem HRS jest założenie stawek proporcjonalnych., Aby zgłosić pojedynczy współczynnik ryzyka, należy założyć, że oba współczynniki ryzyka są stałe. Jeśli nachylenie wykresu ma się zmienić, stosunek zmieni się również w czasie, a zatem nie będzie miał zastosowania jako porównanie prawdopodobieństwa w danym momencie.
rozważmy badanie nowego środka chemioterapeutycznego mającego na celu wydłużenie średniej długości życia pacjentów z określonym rakiem. Zarówno w grupie interwencyjnej, jak i w grupie kontrolnej, 25% zmarło przed 40. tygodniem., Ponieważ obie grupy zmniejszyły się ze 100% przeżywalności do 75% przeżywalności w okresie 40 tygodni, stopień zagrożenia byłby równy, a zatem stopień zagrożenia równy 1. Sugeruje to, że osoba otrzymująca lek jest tak samo narażona na śmierć, jak osoba nie otrzymująca leku w dowolnym momencie.
jest jednak możliwe, że w grupie interwencyjnej wszystkie 25% zmarło w okresie od 6 do 10 tygodni, podczas gdy w grupie kontrolnej wszystkie 25% zmarło w okresie od 1 do 6 tygodni. W tym przypadku porównywanie medianów wykazywałoby wyższą średnią długość życia dla osób przyjmujących lek, mimo że HR nie wykazuje żadnej różnicy., W tym przypadku założenie proporcjonalnego zagrożenia nie powiedzie się, ponieważ wskaźniki zagrożenia zmieniają się (dość dramatycznie) w czasie. W takich przypadkach HR nie ma zastosowania.
ze względu na to, że czasami trudno jest ustalić, czy założenie proporcjonalnego zagrożenia ma rozsądne zastosowanie, oraz ze względu na to, że biorąc HR odcina pierwotny pomiar (hazard rates) jednostki czasu, powszechną praktyką jest zgłaszanie HR w połączeniu z medianą czasu.,
w badaniu oceniającym wyniki prognostyczne dla Rapid Emergency Medicine Score (REMS) i Worthing Physiological Scoring system (WPSS), badacze stwierdzili, że ryzyko 30-dniowej śmiertelności było zwiększone o 30% dla każdej dodatkowej jednostki REMS (HR: 1,28; 95% przedział ufności (CI): 1,23-1,34) i o 60% dla każdej dodatkowej jednostki WPSS (HR: 1,6; 95% CI: 1,5-1,7). W tym przypadku wskaźnik śmierci nie zmienił się, ale raczej system punktacji do przewidywania go, więc można użyć HR. Z przedziałem ufności między 1, 5 A 1.,7 dla wskaźnika zagrożeń WPSS wskazuje, że krzywa śmiertelności dla osób z wyższym WPS maleje w szybszym tempie(około 1,5-1,7 razy). Ponieważ niski koniec interwału jest nadal powyżej 1, jesteśmy pewni, że prawdziwe ryzyko śmierci w ciągu 30 dni jest wyższe dla grupy z wyższymi WPS .
w badaniu z 2018 r.na temat niepohamowanego picia wśród osób z pewnymi czynnikami ryzyka, krzywa przeżycia została skonstruowana kreśląc wskaźnik osiągnięcia niepohamowanego picia dla kontroli, osób z historią rodzinną, płci męskiej, osób z wysoką impulsywnością i osób z wyższą odpowiedzią na alkohol., W przypadku mężczyzn i osób z wywiadem rodzinnym odnotowano statystycznie istotne dowody na wyższy wskaźnik osiągania upijania się (HR 1,74 dla mężczyzn i 1,04 dla osób z wywiadem rodzinnym). Jednak u pacjentów z dużą impulsywnością, mimo że HR wynosił 1, 17, 95% przedział ufności wahał się od 1, 00 do 1, 37. Tak więc, do poziomu ufności 95%, nie można wykluczyć, że HR wynosił 1,00.,
ze względu na obecną przesadę ważne jest, aby unikać przedstawiania RNO jako RR i podobnie ważne jest, aby uznać, że zgłaszane lub rzadko zapewniają dobre przybliżenie względnego ryzyka, ale raczej po prostu zapewniają miarę korelacji.
ze względu na jego zdolność do wyciągania jednoznacznych wniosków i zrozumiałości, RR należy zgłaszać, jeśli to możliwe, jednak w przypadkach, gdy jego założenie przyczynowości jest naruszone (np. badania przypadków i regresja logistyczna), lub może być stosowane.,
HRs są używane z krzywymi przeżycia i zakładają, że współczynniki zagrożenia są równe w czasie. Chociaż przydatne do porównania dwóch wskaźników, należy je zgłaszać z medianą razy, aby uzasadnić założenie proporcjonalnego zagrożenia.
wreszcie, niezależnie od wartości HR/RR / lub statystycznej, interpretacja powinna być dokonana dopiero po ustaleniu, czy wynik dostarcza statystycznie istotnych dowodów prowadzących do konkluzji (określonych przez wartość p lub przedział ufności)., Zapamiętywanie tych zasad i RAM HR/RR / lub minimalizuje wprowadzanie w błąd i zapobiega wyciąganiu błędnych wniosków z wyników opublikowanych badań dotyczących różnych próbek. Rysunek 2 podsumowuje prawidłowe i Nieprawidłowe wykorzystanie tych różnych wskaźników ryzyka.
