intervalles de confiance et valeurs p
afin d’aborder toute discussion sur l’analyse statistique, il est important de comprendre d’abord le concept de statistiques démographiques. En clair, les statistiques démographiques sont les valeurs de toute mesure au sein de la population d’intérêt, et leur estimation est l’objectif de la plupart des études ., Par exemple, dans une étude portant sur les taux d’obésité chez les patients sous un certain médicament, la statistique de la population pourrait être le taux d’obésité moyen pour tous les patients sous le médicament.
cependant, pour identifier cette valeur, il faudrait disposer de données pour chaque individu entrant dans cette catégorie, ce qui n’est pas pratique. Au lieu de cela, un échantillon randomisé peut être collecté, à partir duquel des statistiques d’échantillon peuvent être obtenues. Ces exemples de statistiques servent d’estimations des statistiques démographiques correspondantes et permettent au chercheur de tirer des conclusions sur une population d’intérêt.,
Il existe une limitation importante dans la mesure où ces échantillons construits doivent être représentatifs de la population d’intérêt plus vaste. Bien qu’il existe de nombreuses mesures qui peuvent être prises pour réduire cette limitation, parfois ses effets (soi-disant biais d’échantillonnage ) échappent au contrôle du chercheur. De plus, même dans une situation théorique sans biais d’échantillonnage, la randomisation pourrait donner lieu à un échantillon faussement représentatif. Dans l’exemple précédent, supposons que le taux d’obésité parmi tous les adultes admissibles au médicament était de 25%., Dans un échantillon aléatoire simple de 30 patients de cette population, il y a 19,7% de chances qu’au moins 10 patients soient obèses, ce qui donne un taux d’obésité de l’échantillon de 33,3% ou même plus. Même s’il n’y a pas de relation entre le médicament et les taux d’obésité, il est toujours possible de rencontrer un taux qui semble être différent du taux d’obésité global, qui s’est produit par hasard dans l’échantillonnage seul. Cet effet est la raison pour laquelle les intervalles de confiance et les valeurs p sont rapportés dans la recherche clinique.
les intervalles de Confiance sont des intervalles dans lesquels la population statistique pourrait être., Ils sont construits en fonction de l’échantillon statistique et certaines caractéristiques de l’échantillon d’évaluer comment il est susceptible d’être représentant et sont rapportés à un certain seuil . Un intervalle de confiance à 95% est un intervalle construit de telle sorte que, en moyenne, 95% des échantillons aléatoires contiendraient la statistique de population réelle dans leur intervalle de confiance à 95%. Ainsi, un seuil pour des résultats significatifs est souvent considéré comme 95%, étant entendu que toutes les valeurs dans la plage déclarée sont également valides que la statistique démographique possible.,
la valeur p rapporte des informations similaires d’une manière différente. Plutôt que de construire un intervalle autour d’une statistique d’échantillon, une valeur p indique la probabilité que la statistique d’échantillon ait été produite à partir d’un échantillonnage aléatoire d’une population, compte tenu d’un ensemble d’hypothèses sur la population, appelées « hypothèse nulle” ., En prenant à nouveau l’exemple de l’étude sur les taux d’obésité, le taux d’obésité parmi l’échantillon (un échantillon de patients prenant le médicament) pourrait être rapporté à côté d’une valeur p déterminant les chances qu’un tel taux puisse être produit à partir d’un échantillonnage aléatoire de la population globale de patients admissibles au médicament. Dans le cas de l’étude, l’hypothèse nulle est que le taux d’obésité de la population chez les patients prenant le médicament est égal au taux global d’obésité chez tous les patients éligibles au médicament, soit 25%., Une valeur p à une queue peut être utilisée s’il y a des raisons de croire qu’un effet se produirait dans une seule direction (par exemple, il peut y avoir des raisons de croire que le médicament augmenterait le gain de poids mais ne le diminuerait pas), alors qu’une valeur p à deux queues devrait être utilisée dans tous les autres cas. Lors de l’utilisation d’une distribution symétrique, telle que la distribution normale, les valeurs p à deux queues sont simplement deux fois la valeur p à une queue.
supposons à nouveau qu’un échantillon de 30 patients sous le médicament contient 12 personnes obèses. Avec un test à une queue, notre valeur p est de 0,0216 (en utilisant la distribution binomiale)., Ainsi, nous pouvons dire que notre taux observé de 40% est significativement différent du taux hypothétique de 25% à un niveau de Signification de 0,05. Dans un autre sens, l’intervalle de confiance 95% pour la proportion observée est de 25,6% à 61.07%. Les intervalles de confiance correspondent à des tests à deux queues, où un test à deux queues est rejeté si et seulement si l’intervalle de confiance ne contient pas la valeur associée à l’hypothèse nulle (dans ce cas, 25%).
Si une valeur p calculée est faible, il est probable que la population n’est pas structurée comme indiqué à l’origine dans l’hypothèse nulle., Si nous obtenons une faible valeur p, Nous avons la preuve qu’il y avait un effet ou une raison pour la différence observée – le médicament, dans ce cas. Un seuil de 0,05 (ou 5%) est généralement utilisé, une valeur p devant être inférieure à ce seuil pour que son attribut correspondant soit statistiquement significatif.
taux de Risque
Risque, un autre terme de probabilité, est un autre principe fondamental de l’analyse statistique. La probabilité est une comparaison de l’observation d’un événement spécifique se produisant à la suite des résultats uniques totaux., Un retournement de pièce est un exemple trivial: le risque d’observer une tête est de ½ ou 50%, comme de tous les essais uniques possibles (un retournement entraînant des têtes ou un retournement entraînant des queues), un seul est l’événement d’intérêt (têtes).
utiliser uniquement le risque permet de prédire une seule population. Par exemple, en examinant les taux d’obésité au sein de la population américaine, les CDC ont rapporté que 42,4% des adultes étaient obèses en 2017-2018. Ainsi, le risque qu’un individu aux États-Unis soit obèse est d’environ 42.4% . Cependant, la plupart des études examinent l’effet d’une intervention spécifique ou d’un autre élément (comme la mortalité) sur un autre., Auparavant, nous pensions que le taux d’obésité des patients éligibles était de 25%, mais nous utiliserons ici le 42.4% associé à la population adulte américaine. Supposons que nous observions également un risque de 25% dans un échantillon aléatoire de patients prenant le médicament. Pour conceptualiser l’effet du médicament sur l’obésité, une prochaine étape logique serait de diviser le risque d’obésité dans la population américaine sur le médicament avec le risque d’obésité dans la population américaine, ce qui se traduit par un rapport de risque de 0,590.,
Ce calcul – un ratio de deux risques – est ce que l’on entend par la statistique éponyme du ratio de risque (RR), également appelée risque relatif. Il permet de donner un nombre spécifique pour le risque plus élevé qu’un individu dans une catégorie porte par rapport à un individu dans une autre catégorie. Dans l’exemple, une personne prenant le médicament présente 0,59 fois plus de risques qu’un ADULTE de la population générale des États-Unis., Cependant, nous avons supposé que la population admissible au médicament avait un taux d’obésité de 25% – peut-être que seul un groupe de jeunes adultes, qui peuvent être en meilleure santé en moyenne, sont admissibles à prendre le médicament. Lors de l’étude de l’effet du médicament sur l’obésité, c’est la proportion qui devrait être utilisée comme hypothèse nulle. Si nous observons un taux d’obésité sur le médicament de 40%, avec une valeur p inférieure au niveau de Signification de 0,05, cela prouve que le médicament augmente le risque d’obésité (avec un RR, dans ce scénario, de 1,6)., En tant que tel, il est important de choisir soigneusement l’hypothèse nulle pour faire des prédictions statistiques pertinentes.
avec RR, un résultat de 1 signifie que les deux groupes ont la même quantité de risque, tandis que les résultats non égaux à 1 indiquent qu’un groupe présentait plus de risque qu’un autre, un risque qui est supposé être dû à l’intervention examinée par l’étude (formellement, l’hypothèse de la direction causale).
pour illustrer, nous examinons les résultats d’une étude publiée en 2009 dans le Journal of Stroke and Cerebrovascular Diseases., L’étude rapporte que les patients avec un intervalle QTc électrocardiographique prolongé étaient plus susceptibles de mourir dans les 90 jours par rapport aux patients sans intervalle prolongé (risque relatif =2,5; intervalle de confiance à 95% 1,5-4,1) . Avoir un intervalle de confiance entre 1,5 et 4,1 pour le rapport de risque indique que les patients avec un intervalle QTc prolongé étaient 1,5 à 4,1 fois plus susceptibles de mourir en 90 jours que ceux sans intervalle QTc prolongé.,
un deuxième exemple – dans un article de référence démontrant que la courbe de la pression artérielle dans l’AVC ischémique aigu est en forme de U plutôt Qu’en forme de J , les chercheurs ont constaté que la RR augmentait presque deux fois chez les patients présentant une pression artérielle moyenne (MAP) >140 mmHg ou <100 mmHg (RR=1,8, IC à 95% 1,1-2,9, P=0,027). Avoir un IC de 1,1-2,9 pour le RR signifie que les patients avec une MAP en dehors de la plage de 100-140 mmHg étaient 1,1-2,9 fois plus susceptibles de mourir que ceux qui avaient une MAP initiale dans cette plage.,
pour un autre exemple, une étude de 2018 sur les recrues de la marine australienne a révélé que ceux qui avaient des orthèses préfabriquées (un type de soutien du pied) avaient un risque de 20.3% de subir au moins un effet indésirable, tandis que ceux qui n’en avaient pas avaient un risque de 12.4% . Un rapport de risque ici est donné par 0.203 / 0.124, ou 1.63, suggérant que les recrues avec des orthèses plantaires portaient 1.63 fois le risque d’avoir des conséquences néfastes (par exemple, ampoule de pied, douleur, etc.) que ceux sans. Cependant, la même étude rapporte un intervalle de confiance de 95% pour le rapport de risque de 0,96 à 2,76, avec une valeur p de 0,068., En ce qui concerne l’intervalle de confiance, la plage déclarée à 95% (la norme communément acceptée) comprend des valeurs inférieures à 1, 1 et des valeurs supérieures à 1. En se souvenant que toutes les valeurs sont également susceptibles d’être la statistique de la population, à 95% de confiance, il n’y a aucun moyen d’exclure la possibilité que les orthèses n’aient aucun effet, ont un avantage significatif ou ont un préjudice important. De plus, la valeur p est supérieure à la norme de 0,05, Par conséquent, ces données ne fournissent pas de preuve significative que les orthèses plantaires ont un effet constant sur les événements indésirables tels que les cloques et la douleur., Comme indiqué précédemment, ce n’est pas une coïncidence – s’ils sont calculés en utilisant les mêmes méthodes ou des méthodes similaires et que la valeur p est à deux queues, les intervalles de confiance et les valeurs p rapporteront les mêmes résultats.
lorsqu’ils sont utilisés correctement, les ratios de risque sont une statistique puissante qui permet d’estimer dans une population l’évolution du risque qu’une population supporte par rapport à une autre., Ils sont assez faciles à comprendre (la valeur est combien de fois le risque qu’un groupe porte sur un autre), et avec l’hypothèse de la direction causale, montrent rapidement si une intervention (ou une autre variable testée) a un effet sur les résultats.
Cependant, il y a des limites. Premièrement, le RRs ne peut pas être appliqué dans tous les cas. En raison des risques dans un échantillon est une estimation du risque dans une population, l’échantillon doit être assez représentatif de la population. En tant que telles, les études cas-témoins, du simple fait que les ratios de résultats sont contrôlés, ne peuvent pas faire état d’un ratio de risque., Deuxièmement, comme pour toutes les statistiques discutées ici, la RR est une mesure relative, fournissant des informations sur le risque dans un groupe par rapport à un autre. Le problème ici est qu’une étude où les deux groupes avaient un risque de 0,2% et de 0,1% porte le même RR 2, où les deux groupes avaient un risque de 90% et 45%. Bien que dans les deux cas, il soit vrai que les personnes ayant participé à l’intervention couraient deux fois plus de risque, cela équivaut à seulement 0,1% de risque en plus dans un cas et à 45% de risque en plus dans un autre cas., Ainsi, ne signaler que le RR exagère l’effet dans le premier cas, tout en pouvant même minimiser l’effet (ou au moins le décontextualiser) dans le second cas.
rapports de cotes
alors que le risque indique le nombre d’événements intéressants par rapport au nombre total d’essais, les cotes indiquent le nombre d’événements intéressants par rapport au nombre d’événements Non intéressants. Autrement dit, il rapporte le nombre d’événements à des non-événements., Alors que le risque, tel que déterminé précédemment, de retourner une pièce à la tête est de 1:2 ou 50%, les chances de retourner une pièce à la tête est de 1:1, car il y a un résultat souhaité (événement), et un résultat indésirable (non-événement) (Figure 1).
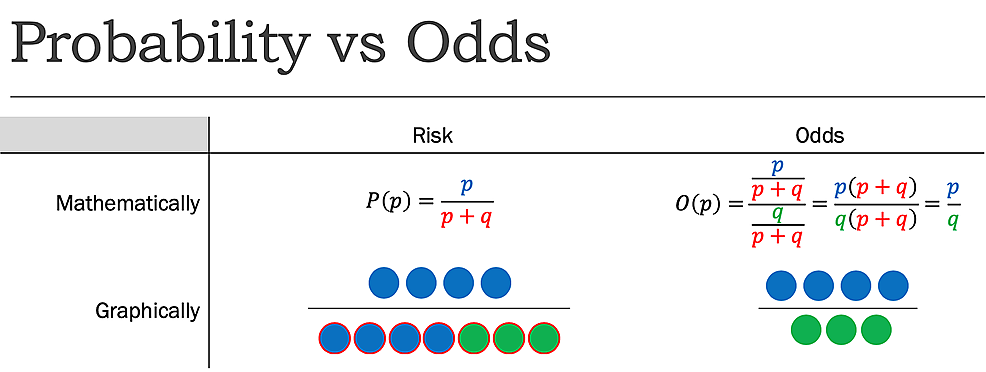
Figure1:probabilité (P) vs. cotes (O) où p=Probabilité de succès et q=probabilité d’échec
tout comme avec RR, où le rapport de deux risques a été pris pour deux groupes distincts, un rapport de deux cotes peut être pris pour deux groupes distincts pour produire un rapport de cotes (ou)., Au lieu de déclarer combien de fois le risque qu’un groupe porte par rapport à l’autre, il indique combien de fois les chances qu’un groupe porte à l’autre.
Pour la plupart, c’est plus difficile statistique à comprendre. Le risque est souvent un concept plus intuitif que les cotes, et donc la compréhension des risques relatifs est souvent préférée à la compréhension des cotes relatives. Cependant, ou ne souffre pas des mêmes limitations de l’hypothèse causale que RR, ce qui le rend plus largement applicable.,
par exemple, les cotes sont une mesure symétrique, ce qui signifie que si le risque n’examine que les résultats en fonction des interventions, les cotes peuvent également examiner les interventions en fonction des résultats. Ainsi, une étude peut être construite où, plutôt que de choisir des groupes d’essais et de mesurer les résultats, les résultats peuvent être choisis et d’autres facteurs peuvent être analysés. Ce qui suit est un exemple d’étude cas-témoin, une situation où RR ne peut pas être utilisé mais peut.
Une étude cas-témoins de 2019 en est un bon exemple., En cherchant à trouver une corrélation potentielle entre une infection par le virus de l’hépatite A (VHA) qui sévit au Canada et un facteur causal, une étude a été construite en fonction du résultat (en d’autres termes, les individus ont été classés en fonction de leur statut VHA, car l ‘ « intervention”, ou l’événement causal, était inconnu). L’étude a examiné les personnes atteintes du VHA et celles qui n’en avaient pas et les aliments qu’elles avaient consommés avant l’infection par le VHA . À partir de cela, plusieurs rapports de cotes ont été construits en comparant un aliment spécifique au statut VHA., Par exemple, les données ont révélé que parmi les sujets qui avaient été exposés à des crevettes/crevettes, huit étaient positifs pour le VHA alors que sept ne l’étaient pas, tandis que pour ceux qui n’avaient pas été exposés, deux étaient positifs pour le VHA alors que 29 ne l’étaient pas. Un rapport de cotes est pris par (8:7)/(2:29) ce qui équivaut à environ 16,6. Les données de l’étude ont rapporté un ou de 15,75, le petit écart provenant probablement de tout ajustement préalable au calcul pour les variables confondantes qui n’a pas été discuté dans le document. Une valeur p de 0,01 a été rapportée, ce qui fournit des preuves statistiques ou est significatif.,
Cela peut être interprété de deux façons. Premièrement, les chances d’exposition aux crevettes chez les personnes atteintes du VHA sont 15,75 fois plus élevées que chez celles qui n’en ont pas. De manière équivalente, la probabilité de VHA-posiitve par rapport au VHA-négatif est 15,75 fois plus élevée chez les personnes exposées aux crevettes que chez celles non exposées.
globalement, OR fournit une mesure de la force d’association entre deux variables sur une échelle de 1 n’étant pas d’association, au-dessus de 1 étant une association positive et au-dessous de 1 étant une association négative., Bien que les deux interprétations précédentes soient correctes, elles ne sont pas aussi directement compréhensibles qu’un RR l’aurait été s’il avait été possible d’en déterminer un. Une autre interprétation est qu’il existe une forte corrélation positive entre l’exposition à la crevette et à la crevette et le VHA.
pour cette raison, dans certains cas spécifiques, il convient d’approximer RR avec OR. Dans de tels cas, l’hypothèse de la maladie rare doit tenir. Autrement dit, une maladie doit être extrêmement rare au sein d’une population., Dans ce cas, le risque de la maladie au sein de la population (p/(p+q)) se rapproche de la probabilité de la maladie au sein de la population (p/q) car p devient insignifiant par rapport à Q. ainsi, le RR et ou convergent à mesure que la population grossit. Cependant, si cette hypothèse échoue, la différence devient de plus en plus exagérée. Mathématiquement, dans les essais p+q, la diminution de p augmente q pour maintenir le même total des essais. Avec le risque, seul le numérateur change, alors qu’avec les cotes, le numérateur et le dénominateur changent dans des directions opposées., Par conséquent, dans les cas où le RR et le ou sont tous deux inférieurs à 1, Le RR sous-estimera le RR, tandis que dans les cas où les deux sont supérieurs à 1, Le RR surestimera le RR.
Une mauvaise déclaration du ou en tant que RR peut donc souvent exagérer les données. Il est important de se rappeler que ou est une mesure relative tout comme RR, et donc parfois un grand ou peut correspondre à une petite différence entre les cotes.
pour la déclaration la plus fidèle, alors, ou ne devrait pas être présenté comme un RR, et ne devrait être présenté comme une approximation de RR si l’hypothèse de la maladie rare peut raisonnablement tenir., Si possible, un RR doit toujours être signalé.
rapports de danger
Les RR et les OR concernent les interventions et les résultats, ce qui rend compte de toute une période d’étude. Cependant, une mesure similaire mais distincte, le rapport de danger (HR), concerne les taux de changement (Tableau 1).
| RR | OU | FC | |
| Objectif | Déterminer la relation dans le statut de risque basé sur une variable. | déterminer l’association entre deux variables., | déterminez comment un groupe change par rapport à un autre. |
| Utilisation | nous Raconte comment une intervention changements des risques. | nous indique s’il existe une association entre une intervention et un risque; estime comment cette association s’applique. | nous indique comment une intervention modifie le taux d’expérience d’un événement. |
| limites | ne s’applique que si le plan d’étude est représentatif de la population. Ne peut pas utiliser sur des études cas-témoins. | peut généralement être appliqué partout, mais pas toujours une statistique utile elle-même. Exagère les risques., | Pour être généralement utile, le taux de changement dans les deux groupes devrait être relativement uniforme. |
| Scénario | Statique – ne considère pas les taux. Résume une étude globale. | statique – ne prend pas en compte les taux. Résume une étude globale. | sur la Base des tarifs. Fournit des informations sur la façon dont une étude progresse dans le temps. |
Table1: risque relatif (RR) vs rapport de cotes (OR) vs, Rapport de danger (HR)
Les HRs sont en tandem avec les courbes de survie, qui montrent la progression temporelle d’un événement au sein d’un groupe, que cet événement soit un décès ou une maladie. Dans une courbe de survie, l’axe vertical correspond à la manifestation d’intérêt et l’axe des abscisses correspond au temps. Le risque de l’événement est alors équivalent à la pente du graphique, ou les événements par temps.
un rapport de danger est simplement une comparaison de deux dangers., Il peut montrer à quelle vitesse deux courbes de survie divergent en comparant les pentes des courbes. Un HR de 1 n’indique aucune divergence-dans les deux courbes, la probabilité de l’événement était également probable à un moment donné. Un HR non égal à 1 indique que deux événements ne se produisent pas à un rythme égal, et le risque d’une personne dans un groupe est différent du risque d’une personne dans un autre à un intervalle de temps donné.
L’hypothèse des taux proportionnels constitue une hypothèse importante pour les HRs., Pour signaler un rapport de danger singulier, il faut supposer que les deux taux de danger sont constants. Si la pente du graphique doit changer, le rapport changera également au fil du temps, et ne s’appliquera donc pas comme comparaison de vraisemblance à un moment donné.
de Considérer l’essai d’un nouvel agent chimiothérapeutique qui cherchent à prolonger l’espérance de vie des patients atteints d’un cancer. Dans le groupe d’intervention et le groupe témoin, 25% étaient morts à la semaine 40., Étant donné que les deux groupes ont diminué de 100% à 75% de survie au cours de la période de 40 semaines, les taux de danger seraient égaux et donc le taux de danger égal à 1. Cela suggère qu’une personne recevant le médicament est tout aussi susceptible de mourir qu’une personne ne recevant pas le médicament à tout moment.
cependant, il est possible que dans le groupe d’intervention, tous les 25% soient morts entre la sixième et la dixième semaine, tandis que pour le groupe témoin, tous les 25% sont morts entre la première et la sixième semaine. Dans ce cas, la comparaison des médianes afficherait une espérance de vie plus élevée pour ceux qui prennent le médicament malgré le HR ne montrant aucune différence., Dans ce cas, l’hypothèse des dangers proportionnels échoue, car les taux de danger changent (de façon assez spectaculaire) au fil du temps. Dans de tels cas, les RH ne sont pas applicables.
étant donné qu’il est parfois difficile de déterminer si l’hypothèse des dangers proportionnels s’applique raisonnablement, et parce que la prise d’un HR dépouille la mesure initiale (taux de danger) de l’Unité de temps, il est courant de déclarer les HR en conjonction avec les temps médians.,
dans une étude évaluant les performances pronostiques du Rapid Emergency Medicine Score (REMS) et du Worthing Physiological Scoring system (wpss), les chercheurs ont constaté que le risque de mortalité à 30 jours était augmenté de 30% pour chaque unité REMS supplémentaire (HR: 1,28; intervalle de confiance à 95% (IC): 1,23-1,34) et de 60% pour chaque unité WPSS supplémentaire (HR: 1,6; IC à 95%: 1,5-1,7). Dans ce cas, le taux de mortalité n’a pas changé, mais plutôt le système de notation pour le prédire, de sorte que le HR peut être utilisé. Ayant un intervalle de confiance compris entre 1,5 et 1.,7 pour le rapport des dangers du SSPM indique que la courbe de mortalité des personnes ayant un SSP plus élevé diminue à un rythme plus rapide (environ 1,5 à 1,7 fois). Étant donné que l’extrémité inférieure de l’intervalle est toujours supérieure à 1, Nous sommes convaincus que le risque réel de décès dans les 30 jours est plus élevé pour le groupe avec un WPS plus élevé .
dans une étude de 2018 sur la consommation excessive d’alcool chez les personnes présentant certains facteurs de risque, une courbe de survie a été construite pour tracer le taux de consommation excessive d’alcool chez les témoins, ceux ayant des antécédents familiaux, le sexe masculin, ceux ayant une forte impulsivité et ceux ayant une réponse plus élevée à l’alcool., Pour les hommes et ceux ayant des antécédents familiaux, des preuves statistiquement significatives d’un taux plus élevé de consommation excessive d’alcool ont été rapportées (une HR de 1,74 pour les hommes et de 1,04 pour ceux ayant des antécédents familiaux) . Cependant, pour ceux ayant une impulsivité élevée, bien que la HR soit de 1,17, l’intervalle de confiance de 95% variait de 1,00 à 1,37. Ainsi, à un niveau de confiance de 95%, Il est impossible d’exclure que le HR était de 1,00.,
en raison de l’exagération présente, il est important d’éviter de représenter les SRO comme des RR, et de même, il est important de reconnaître qu’un ou déclaré fournit rarement une bonne approximation des risques relatifs, mais fournit simplement une mesure de la corrélation.
en raison de sa capacité à tirer des conclusions fermes et de sa compréhensibilité, RR devrait être signalé si possible, cependant dans les cas où son hypothèse de causalité est violée (comme les études cas-témoins et la régression logistique), ou peut être utilisé.,
Les HR sont utilisées avec des courbes de survie et supposent que les taux de danger sont égaux dans le temps. Bien qu’il soit utile de comparer deux taux, ils doivent être déclarés avec des temps médians pour justifier l’hypothèse de risques proportionnels.
enfin, quelle que soit la valeur de la HR/RR/ou de la statistique, une interprétation ne devrait être faite qu’après avoir déterminé si le résultat fournit des preuves statistiquement significatives vers une conclusion (comme déterminé par la valeur p ou l’intervalle de confiance)., Se souvenir de ces principes et du cadre de HR/RR/ou minimise les fausses déclarations et empêche de tirer des conclusions incorrectes des résultats d’une étude publiée concernant divers échantillons. La Figure 2 résume l’utilisation correcte et incorrecte de ces divers ratios de risque.
