intervalos de confianza y valores p
con el fin de entretener cualquier discusión sobre el análisis estadístico, es importante entender primero el concepto de estadísticas de población. Claramente, las estadísticas de población son los valores de cualquier medida dentro de la población de interés, y estimarlos es el objetivo de la mayoría de los estudios ., Por ejemplo, en un estudio que analiza las tasas de obesidad para los pacientes que toman un determinado medicamento, la estadística de la población podría ser la tasa promedio de obesidad para todos los pacientes que toman el medicamento.
sin embargo, identificar este valor requeriría tener datos para cada individuo que cae en esta categoría, lo cual no es práctico. En su lugar, se puede recopilar una muestra aleatoria, a partir de la cual se pueden obtener estadísticas de la muestra. Estas estadísticas de muestra sirven como estimaciones de las estadísticas de población correspondientes y permiten a un investigador hacer conclusiones sobre una población de interés.,
existe una limitación significativa en que estas muestras construidas deben ser representativas de la mayor población de interés. Si bien hay muchos pasos que se pueden tomar para reducir esta limitación, a veces sus efectos (el llamado sesgo de muestreo ) van más allá del control del investigador. Además, incluso en una situación teórica sin sesgo de muestreo, la aleatorización podría resultar en una muestra tergiversada. En el ejemplo anterior, supongamos que la tasa poblacional de obesidad entre todos los adultos elegibles para el medicamento fue del 25%., En una muestra aleatoria simple de 30 pacientes de esta población, hay una probabilidad de 19,7% de que al menos 10 pacientes sean obesos, lo que resulta en una tasa de obesidad de la muestra de 33,3% o incluso mayor. Incluso si no hay relación entre la medicación y las tasas de obesidad, todavía es posible encontrar una tasa que parece ser diferente de la tasa general de obesidad, que ocurrió a través de la aleatoriedad en el muestreo solo. Este efecto es la razón por la que se reportan intervalos de confianza y valores p en la investigación clínica.
los intervalos de confianza son intervalos en los que la estadística poblacional podría encontrarse., Se construyen sobre la base de la estadística de la muestra y ciertas características de la muestra que miden la probabilidad de que sea representativa y se informan a un cierto umbral . Un intervalo de confianza del 95% es un intervalo construido de tal manera que, en promedio, el 95% de las muestras aleatorias contendría la estadística de la población verdadera dentro de su intervalo de confianza del 95%. Por lo tanto, un umbral para resultados significativos a menudo se toma como 95%, con el entendimiento de que todos los valores dentro del rango reportado son igualmente válidos como la estadística de población posible.,
el valor p informa información similar de una manera diferente. En lugar de construir un intervalo alrededor de una estadística de la muestra, un valor p informa la probabilidad de que la estadística de la muestra se produjo a partir de un muestreo aleatorio de una población, dado un conjunto de suposiciones sobre la población, conocida como la «hipótesis nula» ., Tomando el ejemplo del estudio sobre las tasas de obesidad nuevamente, la tasa de obesidad entre la muestra (una muestra de pacientes en el medicamento) podría ser reportada junto con un valor p que determina la posibilidad de que tal tasa pueda ser producida a partir del muestreo aleatorio de la población general de pacientes elegibles para el medicamento. En el caso del estudio, la hipótesis nula es que la tasa poblacional de obesidad entre los pacientes que toman el medicamento es igual a la tasa global de obesidad entre todos los pacientes elegibles para el medicamento, es decir, 25%., Un valor p de una cola se puede utilizar si hay razones para creer que un efecto ocurriría en una sola dirección (por ejemplo, puede haber razones para creer que el medicamento aumentaría el aumento de peso pero no lo disminuiría), mientras que un valor p de dos colas se debe utilizar en todos los demás casos. Cuando se utiliza una distribución simétrica, como la distribución normal, los valores p de dos colas son simplemente dos veces el valor p de una cola.
supongamos nuevamente que una muestra de 30 pacientes en el medicamento contiene 12 individuos obesos. Con una prueba de una cola, nuestro valor de p es 0.0216 (usando la distribución binomial)., Así, podemos decir que nuestra tasa observada de 40% es significativamente diferente de la tasa hipotética de 25% en un nivel de significancia de 0,05. En otro sentido, el intervalo de confianza del 95% para la proporción observada es de 25,6% a 61,07%. Los intervalos de confianza corresponden a pruebas de dos colas, donde una prueba de dos colas se rechaza si y solo si el intervalo de confianza no contiene el valor asociado con la hipótesis nula (en este caso, 25%).
si un valor p calculado es pequeño, es probable que la población no esté estructurada como se declaró originalmente en la hipótesis nula., Si obtenemos un valor p bajo, tenemos evidencia de que hubo algún efecto o razón para la diferencia observada – la medicación, en este caso. Normalmente se utiliza un umbral de 0,05 (o 5%), con un valor de p que tiene que estar por debajo de este umbral para que su atributo correspondiente sea estadísticamente significativo.
cocientes de riesgo
riesgo, otro término para la probabilidad, es otro principio fundamental del análisis estadístico. La probabilidad es una comparación de la observación de un evento específico que ocurre como resultado de los resultados únicos totales., Un tirón de moneda es un ejemplo trivial: el riesgo de observar una cara es ½ o 50%, como de todos los ensayos únicos posibles (un tirón que resulta en cara o un tirón que resulta en colas), solo uno es el evento de interés (cabezas).
usar solo riesgo permite hacer predicciones sobre una sola población. Por ejemplo, al observar las tasas de obesidad dentro de la población de los Estados Unidos, los CDC informaron que el 42.4% de los adultos eran obesos en 2017-2018. Por lo tanto, el riesgo de que una persona en los EE.UU. sea obesa es de alrededor del 42,4% . Sin embargo, la mayoría de los estudios analizan el efecto de una intervención específica u otro elemento (como la mortalidad) en otro., Anteriormente, suponíamos que la tasa de obesidad de los pacientes elegibles era del 25%, pero aquí usaremos el 42.4% asociado con la población adulta de los Estados Unidos. Supongamos que observamos un riesgo del 25% en una muestra aleatoria de pacientes en el medicamento también. Para conceptualizar el efecto de la medicación sobre la obesidad, un siguiente paso lógico sería dividir el riesgo de obesidad en la población estadounidense con el riesgo de obesidad en la población estadounidense, lo que resulta en una relación de riesgo de 0,590.,
este cálculo-una relación de dos riesgos-es lo que se entiende por la estadística de la relación de riesgo del mismo nombre (RR), también conocida como riesgo relativo. Permite dar un número específico de cuánto más riesgo tiene un individuo en una categoría en comparación con un individuo en otra categoría. En el ejemplo, un individuo que toma el medicamento tiene 0.59 veces más riesgo que un ADULTO de la población general de los Estados Unidos., Sin embargo, hemos asumido que la población elegible para el medicamento tenía una tasa de obesidad del 25% – tal vez solo un grupo de adultos jóvenes, que pueden ser más saludables en promedio, son elegibles para tomar el medicamento. Al investigar el efecto de la medicación sobre la obesidad, esta es la proporción que debe utilizarse como hipótesis nula. Si observamos una tasa de obesidad en la medicación del 40%, con un valor de p menor que el nivel de significancia de 0.05, esto es evidencia de que la medicación aumenta el riesgo de obesidad (con un RR, en este escenario, de 1.6)., Como tal, es importante elegir cuidadosamente la hipótesis nula para hacer predicciones estadísticas relevantes.
con RR, un resultado de 1 significa que ambos grupos tienen la misma cantidad de riesgo, mientras que los resultados no iguales a 1 indican que un grupo tuvo más riesgo que otro, un riesgo que se supone que se debe a la intervención examinada por el estudio (formalmente, la suposición de dirección causal).
para ilustrar, nos fijamos en los resultados de un estudio de 2009 publicado en el Journal of Stroke and Cerebrovascular Diseases., El estudio informa que los pacientes con un intervalo QTc electrocardiográfico prolongado tenían más probabilidades de morir en 90 días en comparación con los pacientes sin un intervalo prolongado (riesgo relativo =2,5; intervalo de confianza del 95% 1,5-4,1) . Tener un intervalo de confianza entre 1,5 y 4,1 para la razón de riesgo indica que los pacientes con un intervalo QTc prolongado tenían 1,5-4,1 veces más probabilidades de morir en 90 días que aquellos sin un intervalo QTc prolongado.,
un segundo ejemplo – en un artículo de referencia que demuestra que la curva de presión arterial en el accidente cerebrovascular isquémico agudo es en forma de U en lugar de en forma de J , Los investigadores encontraron que el RR aumentó casi dos veces en pacientes con presión arterial media (PAM) >140 mmHg o <100 mmHg (RR=1,8, IC del 95% 1,1-2,9, P=0,027). Tener un IC de 1,1 – 2,9 para el RR significa que los pacientes con una PAM fuera del rango de 100-140 mmHg tenían 1,1-2,9 veces más probabilidades de morir Que aquellos que tenían PAM inicial dentro de este rango.,
por otro ejemplo, un estudio de 2018 sobre reclutas navales Australianos encontró que aquellos con ortesis prefabricadas (un tipo de soporte para pies) tenían un riesgo del 20,3% de sufrir al menos un efecto adverso, mientras que aquellos sin ellos tenían un riesgo del 12,4% . Una relación de riesgo aquí se da por 0,203 / 0,124, o 1,63, lo que sugiere que los reclutas con órtesis del pie tenían 1,63 veces el riesgo de tener alguna consecuencia adversa (por ejemplo, ampollas en el pie, dolor, etc.).) que los que no. Sin embargo, el mismo estudio reporta un intervalo de confianza del 95% para la razón de riesgo de 0,96 a 2,76, con un valor de p de 0,068., Mirando el intervalo de confianza, el 95% reportado rango (el estándar comúnmente aceptado) incluye valores por debajo de 1, 1 y valores por encima de 1. Recordando que todos los valores tienen la misma probabilidad de ser la estadística de la población, con una confianza del 95%, no hay manera de excluir la posibilidad de que las órtesis de pie no tengan efecto, tengan un beneficio significativo o tengan un perjuicio significativo. Además, el valor de p es mayor que el estándar de 0,05, Por lo tanto, estos datos no proporcionan evidencia significativa de que las órtesis del pie tengan un efecto consistente en eventos adversos como ampollas y dolor., Como se indicó anteriormente, esto no es una coincidencia: si se calculan utilizando los mismos métodos o métodos similares y el valor de p es de dos colas, los intervalos de confianza y los valores de p reportarán los mismos resultados.
Cuando se utilizan correctamente, los ratios de riesgo son una estadística poderosa que permite una estimación en una población del cambio en el riesgo que una población tiene sobre otra., Son bastante fáciles de entender (el valor es cuántas veces el riesgo tiene un grupo sobre otro), y con la suposición de la dirección causal, muestran rápidamente si una intervención (u otra variable probada) tiene un efecto en los resultados.
sin Embargo, hay limitaciones. En primer lugar, el RRs no puede aplicarse en todos los casos. Dado que el riesgo en una muestra es una estimación del riesgo en una población, la muestra debe ser razonablemente representativa de la población. Como tal, los estudios de casos y controles, por simple virtud del hecho de que las proporciones de resultados están controladas, no pueden tener una proporción de riesgo reportada., En segundo lugar, como con todas las estadísticas discutidas aquí, el RR es una medida relativa, que proporciona información sobre el riesgo en un grupo en relación con otro. El problema aquí es que un estudio en dos grupos tenían un riesgo de 0.2% y 0.1% lleva el mismo RR, 2, como uno donde dos grupos tenían un riesgo del 90% y 45%. Si bien en ambos casos es cierto que las personas con intervención corrían el doble de riesgo, esto equivale a solo un 0,1% más de riesgo en un caso, mientras que un 45% más de riesgo en otro caso., Por lo tanto, informar solo el RR exagera el efecto en la primera instancia, mientras que potencialmente incluso minimiza el efecto (o al menos descontextualizarlo) en la segunda instancia.
Odds ratios
mientras que risk reporta el número de eventos de interés en relación con el número total de ensayos, odds reporta el número de eventos de interés en relación con el número de eventos no de interés. Dicho de otra manera, informa el número de eventos a No eventos., Mientras que el riesgo, como se determinó anteriormente, de voltear una moneda para ser cara es 1:2 o 50%, las probabilidades de voltear una moneda para ser cara es 1:1, ya que hay un resultado deseado (evento) y un resultado no deseado (no evento) (Figura 1).
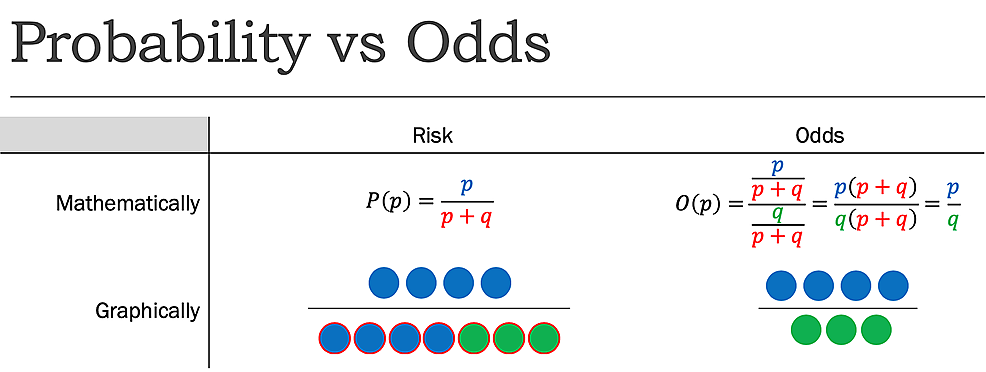
Figura 1:Probabilidad (P) vs Probabilidades (S) donde p=probabilidad de éxito q=probabilidad de fracaso
al igual que con RR, donde la relación de dos de los riesgos tomados por separado en dos grupos, una proporción de dos probabilidades pueden ser adoptadas por dos grupos separados para producir una odds ratio (or)., En lugar de informar cuántas veces el riesgo de un grupo tiene relación con el otro, informa cuántas veces las probabilidades de un grupo tiene con el otro.
para la mayoría, Esta es una estadística más difícil de entender. El riesgo es a menudo un concepto más intuitivo que las probabilidades, por lo que a menudo se prefiere comprender los riesgos relativos a comprender las probabilidades relativas. Sin embargo, o no sufre de las mismas limitaciones de suposición causal que RR, por lo que es más ampliamente aplicable.,
por ejemplo, las probabilidades son una medida simétrica, lo que significa que mientras que el riesgo solo examina los resultados de determinadas intervenciones, las probabilidades también pueden examinar las intervenciones de determinados resultados. Por lo tanto, se puede construir un estudio donde, en lugar de elegir grupos de ensayo y medir los resultados, se pueden elegir los resultados y se pueden analizar otros factores. El siguiente es un ejemplo de un estudio de casos y controles, una situación en la que RR no se puede utilizar pero o puede.
Un estudio de casos y controles de 2019 demuestra un buen ejemplo., Buscando encontrar una posible correlación entre una infección por el virus de la hepatitis A (VHA) prominente en Canadá y algún factor causante, se construyó un estudio basado en el resultado (en otras palabras, los individuos fueron categorizados según su estado de VHA, ya que la «intervención», o evento causal, era desconocida). El estudio analizó a las personas con VHA y las que no y qué alimentos habían comido antes de la infección por VHA . A partir de esto, se construyeron múltiples odds ratio comparando un alimento específico con el estado de VHA., Por ejemplo, los datos encontraron que entre aquellos sujetos que tuvieron exposición a camarones/gambas, ocho fueron positivos para VHA mientras que siete no lo fueron, mientras que para aquellos sin exposición dos fueron positivos para VHA mientras que 29 no lo fueron. Una razón de probabilidades se toma por (8:7)/(2:29) que es igual a aproximadamente 16.6. Los datos del estudio reportaron una OR de 15.75, con la pequeña discrepancia probablemente originada por cualquier ajuste previo al cálculo para variables de confusión que no se discutió en el artículo. Se reportó un valor de p de 0,01, lo que proporciona evidencia estadística para este o ser significativo.,
esto se puede interpretar de dos maneras iguales. En primer lugar, las probabilidades de exposición de camarón/camarón para aquellos con VHA son 15,75 veces mayores que para aquellos sin VHA. De manera equivalente, las probabilidades de VHA-posiitve frente a VHA-negativo son 15,75 veces mayores para aquellos expuestos a camarones/gambas que para aquellos no expuestos.
En general, OR proporciona una medida de la fuerza de asociación entre dos variables en una escala de 1 siendo no asociación, por encima de 1 siendo una asociación positiva, y por debajo de 1 siendo una asociación negativa., Si bien las dos interpretaciones anteriores son correctas, no son tan directamente comprensibles como lo habría sido un RR, si hubiera sido posible determinar una. Una interpretación alternativa es que existe una fuerte correlación positiva entre la exposición de camarón/camarón y el VHA.
debido a esto, en algunos casos específicos, es apropiado aproximar RR con OR. En tales casos, el supuesto de enfermedad rara debe mantenerse. Es decir, una enfermedad debe ser extremadamente rara dentro de una población., En este caso, el riesgo de la enfermedad dentro de la población (p/(p+q)) se acerca a las probabilidades de la enfermedad dentro de la población (p/q) A medida que p se vuelve insignificante en relación con q. Por lo tanto, el RR y OR convergen a medida que la población aumenta. Sin embargo, si esta suposición falla, la diferencia se vuelve cada vez más exagerada. Matemáticamente, en los ensayos p+q, la disminución de p aumenta q para mantener el mismo total de ensayos. Con el riesgo, solo cambia el numerador, mientras que con las probabilidades tanto el numerador como el denominador cambian en direcciones opuestas., En consecuencia, para los casos en que el RR y el OR estén ambos por debajo de 1, EL OR subestimará el RR, mientras que para los casos en que ambos estén por encima de 1, EL OR sobreestimará el RR.
Los informes erróneos del OR como el RR, entonces, a menudo pueden exagerar los datos. Es importante recordar que OR es una medida relativa igual que RR, y por lo tanto a veces un OR grande puede corresponder con una pequeña diferencia entre odds.
para los informes más fieles, entonces, o no debe presentarse como un RR, y solo debe presentarse como una aproximación de RR si el supuesto de enfermedad rara puede sostenerse razonablemente., Si es posible, siempre se debe informar un RR.
Hazard ratios
tanto RR como OR se refieren a intervenciones y resultados, por lo que se notifican a lo largo de todo el período del estudio. Sin embargo, una medida similar pero distinta, el hazard ratio (HR), se refiere a las tasas de cambio (Tabla 1).
| RR | O | RRHH | |
| Objetivo | Determinar la relación en estado de riesgo basado en alguna variable. | Determinar la asociación entre dos variables., | Determine cómo cambia un grupo en relación con otro. |
| Use | nos dice cómo una intervención cambia los riesgos. | nos dice si hay una asociación entre una intervención y el riesgo; estima cómo se aplica esta asociación. | nos dice cómo una intervención cambia la tasa de experimentar un evento. |
| limitaciones | solo aplicables si el diseño del estudio es representativo de la población. No se puede usar en estudios de casos y controles. | generalmente se puede aplicar en todas partes, pero no siempre es una estadística útil en sí. Exagera los riesgos., | para ser típicamente útil, la tasa de cambio dentro de dos grupos debe ser relativamente consistente. |
| Timeline | Static-no tiene en cuenta las tasas. Resume un estudio general. | estática – no tiene en cuenta las tasas. Resume un estudio general. | basado en tarifas. Proporciona información sobre la forma en que un estudio progresa con el tiempo. |
Tabla1: riesgo Relativo (RR) vs Odds Ratio (or) vs, La razón de riesgos (HR)
Las Horas están en tándem con curvas de supervivencia, que muestran la progresión temporal de algún evento dentro de un grupo, ya sea que ese evento sea la muerte o contraer una enfermedad. En una curva de supervivencia, el eje vertical corresponde al evento de interés y el eje horizontal corresponde al tiempo. El riesgo del evento es entonces equivalente a la pendiente del gráfico, o los eventos por tiempo.
un hazard ratio es simplemente una comparación de dos peligros., Puede mostrar la rapidez con la que dos curvas de supervivencia divergen a través de la comparación de las pendientes de las curvas. Una FC de 1 indica que no hay divergencia – dentro de ambas curvas, la probabilidad del evento era igualmente probable en un momento dado. Un HR No igual a 1 indica que dos eventos no están ocurriendo a una tasa igual, y el riesgo de un individuo en un grupo es diferente al riesgo de un individuo en otro en un intervalo de tiempo dado.
una suposición importante que hace HRs es la suposición de tasas proporcionales., Para comunicar una razón de riesgo singular, debe suponerse que las dos tasas de riesgo son constantes. Si la pendiente del gráfico va a cambiar, la relación también cambiará con el tiempo, y por lo tanto no se aplicará como una comparación de probabilidad en un momento dado.
considere el ensayo de un nuevo agente quimioterapéutico que busca extender la esperanza de vida de los pacientes con un cáncer específico. Tanto en el grupo de intervención como en el grupo control, el 25% había muerto en la semana 40., Dado que ambos grupos disminuyeron de 100% a 75% de supervivencia durante el período de 40 semanas, las tasas de riesgo serían iguales y, por lo tanto, la tasa de riesgo igual a 1. Esto sugiere que un individuo que recibe el medicamento es tan probable que muera como uno que no recibe el medicamento en cualquier momento.
sin embargo, es posible que en el grupo de intervención, todos los 25% murieron entre las semanas seis a 10, mientras que para el grupo de control, todos los 25% murieron dentro de las semanas uno a seis. En este caso, la comparación de las medianas mostraría una mayor esperanza de vida para los que toman el medicamento a pesar de que la FC no muestra ninguna diferencia., En este caso, el supuesto de riesgos proporcionales falla, ya que las tasas de riesgo cambian (bastante dramáticamente) con el tiempo. En casos como este, HR no es aplicable.
debido a que a veces es difícil determinar si la suposición de riesgos proporcionales se aplica razonablemente, y debido a que tomar una FC elimina la medición original (tasas de riesgo) de la unidad de tiempo, es una práctica común reportar la FC junto con la mediana de los tiempos.,
en un estudio que evaluó el rendimiento pronóstico del Rapid Emergency Medicine Score (REMS) y el Worthing Physiological Scoring system (WPSS), los investigadores encontraron que el riesgo de mortalidad a 30 días aumentó en un 30% para cada unidad adicional de REMS (HR: 1,28; intervalo de confianza (IC) del 95%: 1,23-1,34) y en un 60% para cada unidad adicional de WPSS (HR: 1,6; IC del 95%: 1,5-1,7). En este caso, la tasa de mortalidad no cambió, sino el sistema de puntuación para predecirla, por lo que se puede utilizar la FC. Tener un intervalo de confianza entre 1,5 y 1.,7 para el WPSS hazards ratio indica que la curva de mortalidad para aquellos con un WPS más alto disminuye a un ritmo más rápido (aproximadamente 1.5-1.7 veces). Dado que el extremo inferior del intervalo todavía está por encima de 1, estamos seguros de que el verdadero riesgo de muerte dentro de 30 días es mayor para el grupo con mayor WPS .
en un estudio de 2018 sobre el consumo excesivo de alcohol entre individuos con ciertos factores de riesgo, se construyó una curva de supervivencia que traza la tasa de logro del consumo excesivo de alcohol para controles, aquellos con antecedentes familiares, sexo masculino, aquellos con alta impulsividad y aquellos con una mayor respuesta al alcohol., Para los hombres y aquellos con antecedentes familiares, se informó de evidencia estadísticamente significativa de una mayor tasa de logro de consumo excesivo de alcohol (un HR de 1,74 para los hombres y 1,04 para aquellos con antecedentes familiares) . Sin embargo, para aquellos con alta impulsividad, aunque la FC fue de 1,17, el intervalo de confianza del 95% varió de 1,00 a 1,37. Así, a un nivel de confianza del 95%, es imposible descartar que la FC Fuera de 1,00.,
debido a la exageración presente, es importante evitar representar ORs como RRs, y de manera similar, es importante reconocer que un Or reportado rara vez proporciona una buena aproximación de los riesgos relativos, sino que simplemente proporciona una medida de correlación.
debido a su capacidad de hacer conclusiones firmes y comprensibilidad, RR debe ser reportado si es posible, sin embargo en los casos en que su suposición de causalidad es violada (tales como estudios de casos y controles y regresión logística), o puede ser utilizado.,
Las horas se utilizan con las curvas de supervivencia y suponen que las tasas de riesgo son iguales en el tiempo. Si bien son útiles para comparar dos tasas, deben reportarse con tiempos medios para justificar la suposición de riesgos proporcionales.
finalmente, independientemente del valor de la HR/RR/o Estadística, una interpretación solo debe hacerse después de determinar si el resultado proporciona evidencia estadísticamente significativa hacia una conclusión (según lo determinado por el valor de p o intervalo de confianza)., Recordar estos principios y el marco de HR/RR/OR minimiza la tergiversación e impide sacar conclusiones incorrectas de los resultados de un estudio publicado sobre varias muestras. En la figura 2 se resume el uso correcto e incorrecto de estos diversos coeficientes de riesgo.
